zengl编程语言v0.0.8第二代语法解析函数
zenglong 2012-11-11 10:45:44
前几节,编译器里的parser.c用的构建语法树的express函数,不方便扩展新的运算符,而且也不方便进行优先级的比较,BUG也多,所以这一节 将采用新的语法解析函数express2来生成AST抽象语法树,...
前几节,编译器里的parser.c用的构建语法树的express函数,不方便扩展新的运算符,而且也不方便进行优先级的比较,BUG也多,所以这一节 将采用新的语法解析函数express2来生成AST抽象语法树,原来的express函数并没有删除,先保留着以作参考。
本节v0.0.8版本的源代码下载地址为:http://pan.baidu.com/share/link?shareid=100236&uk=940392313 (此为百度云盘的共享链接地址),访问该地址可以看到三个文件: zengl_lang_v0.0.8_forXP.rar (XP系统下的vs2008解决方案和源代码), zengl_language_v0.0.8_forLinux.tar.gz (Linux系统下的源代码和makefile) ,v0.0.8-v0.0.7-diffs.txt (v0.0.8和v0.0.7的代码变化情况)。
SourceForge.net上的仓库地址为:https://sourceforge.net/projects/zengl/files/ 从里面可以看到各个版本的代码压缩包,比如本节的zengl_lang_v0.0.8_forXP.rar ,zengl_language_v0.0.8_forLinux.tar.gz,v0.0.8-v0.0.7-diffs.txt 。
先来看下本版本的描述 (在linux代码包里的usage.txt里有这段描述)
v0.0.8的版本,该版本采用优先级的方法重写了表达式的算法,并且让表达式可以支持大于等于之类的6个比较运算符以及与或非3个逻辑运算符。
main.c文件中增加了>,==,<,<=,>=,!= 6个比较运算符以及&&,||,! 3个逻辑运算符的token的识别。同时该commit中以字母开头的字母,数字,下划线组成的字串都是有效的标示符。
parser.c文件是本次修改最多的文件,也是表达式语法树算法的最重要的核心部分,该commit抛弃了以前使用的express函数,而是重写了个 express2函数,并且将print之类的reserve statement保留语句的解析从原express2中剥离出来,如print语句是buildAST调用statement再调用单独的 print_stmt函数,在该函数内再调用express2函数,这样statement语句的解析就不会影响到普通表达式的解析。express2函 数采用优先级的算法,优先级越高就越在语法树的底层,就越先被执行,低优先级的操作则越靠近树的顶层,就越后执行。在实现优先级的算法时因为要进行前后操 作符的优先级的比较,所以引入了堆栈的概念,当低优先级的符号碰到高优先级的符号,要递归调用express2函数之前先调用push_stack进行压栈操作,这样在express2里如果高优先级碰到低优先级时,可以通过pop_stack函数将之前压入的低优先级的操作符弹出和当前的低优先级的操作符进行比较,谁的优先级更高些,就先执行谁的操作。赋值操作符是个特例,除了第一个赋值操作符是优先级最低的外,其余表达式中间的赋值操作符的优先级都是最高的。优先级顺序:表达式中间的赋值符 > ‘!’取反逻辑运算符 > 乘除 > 加减 > 比较运算符 > &&,|| 逻辑运算符 > 第一个赋值运算符。
global.h中增加了比较运算符和逻辑运算符以及与优先级相关的一些数据类型的定义。
assemble.c中增加了比较运算符和逻辑运算符相关的汇编指令。如大于操作符就输出"GREAT"指令等。
run.c中将减法MINIS指令的执行放在单独op_minis函数里, 这样,GREAT之类的比较指令就可以借用op_minis函数,先将AX,BX里的值相减,如果AX-BX>0则GREAT指令执行的结果就是将 AX设为1否则设为0,即:如果AX大于BX则AX设为TRUE(就是1)。GREAT,LESS之类的比较指令统一放在op_relation函数里, 方便维护和处理。逻辑运算相关的&&,||,!的执行也统一放在op_logic函数里。
run.h里增加了对应的比较运算符以及逻辑运算符的枚举类型的定义。
作者:zenglong
时间:2012年2月18日 (事情太多,该版本的发布迟了很久,现在都11月份了,时间过得真快)
在源代码文件里包含了很多注释,方便调试分析研究,先来看下几个主要文件源代码的变化情况。
该版本最主要的代码文件是parser.c :
*
新版语法分析函数,采用堆栈和优先级来生成语法树。这是编译引擎里最核心的部分,也是算法最复杂的部分,因为要考虑实际中可能出现的各种可能的语法情况。
*/
int express2()
{
Node_Type *nodes = AST_nodes.nodes;
int state = START;
int p=-1;
int tmpcount = 0;
int tmpnode = -1;
STACK_Type retstack;
while(state!=DOWN)
{
addcurnode();
switch(state)
{
case START:
if(ISTOKCATE(OP_FACTOR))
{
p = curnode;
state = INID;
}
else if(ISTOKTYPE(LBRACKET))
{
if(ISTOKTYPEXOR6(curnode+1,ID,NUM,FLOAT,STR,LBRACKET,REVERSE)) //当左括号右边是标示符,数字,字符串,左括号,取反符之类的有效的token时递归调用express2,生成括号里的语法树。
{
tmpcount = stacklist.count; //在递归express2之前,先将当前栈的栈顶记录下来,因为最后一个元素就是下一次要弹出的元素,即为堆栈顶部,所以只需将stacklist的count保存下来即可。递归结束后,直接恢复stacklist的count值即可恢复递归前的堆栈环境。
tmpnode = curnode; //将当前左括号的节点记录下来,后面会用到。
push_stack(-1); //将-1压入堆栈,-1比任何节点的优先级都低,这样在生成括号里的语法树时,在进行优先级比较时就不会受到左括号左边节点优先级的影响。
p = express2(); //递归express2函数生成括号里的语法树。
stacklist.count = tmpcount; //恢复递归之前的堆栈空间。
curnode++; //递归结束后,curnode指向右括号之前的节点,所以将其加一,使其指向右括号用于下面的判断。
if(!ISTOKTYPE(RBRACKET)) //判断括号是否完整
syntax_error("syntax error start no right bracket (语法错误:只有左括号,没有右括号!)");
else if(ISTOKTYPEXOR(tmpnode-1,ASSIGN,LBRACKET)) //如果左括号的左边是赋值节点或左括号,就将state设为INID,这样括号表达式生成的AST语法树就会以标示符的形式参与括号后的语法树的生成工作。否则括号后的节点就会丢失,而无法生成正确的语法树。
state = INID; //例如 a = ((a+b)*5) 在生成a+b的语法树后因为state设为了INID就会继续和*5生成语法树,否则就只会生成a+b而丢失乘法节点和5的节点。
else if(ISTOKTYPEX(curnode+1,ASSIGN)) //括号后面不能接赋值符号。如(a+b) = 5 是错误的表达式。
syntax_error("syntax error ')' can't with '=' (语法错误:括号后面不能接赋值运算符!)");
else
state = DOWN; //完成括号表达式的AST则返回。
}
else
syntax_error("syntax error left bracket (语法错误:左括号右边的节点不是允许的节点!)");
}
else if(ISTOKTYPE(REVERSE)) //如果以取反运算符开始,就将p父节点设为当前节点,并进入INOP状态。
{
p = curnode;
state = INOP;
}
........ //限于篇幅,N多代码省略 。。。
}//switch(state)
}//while
return p;
}
因为篇幅有限,所以这里只给出些代码片段,在源代码里都有这些注释信息,所以就不占用篇幅了。
这里就举个例子,来说明新版的express2函数的原理。尽管注释已经很详细了,不过还不够直观。先来看一条脚本:
print 'a is ' + a = 5 + 8 * 7 / 3 - 2;
这个例子并不在test.zl测试代码中,但是大家可以自己建一个test2.zl之类的文件,里面放这条代码,再用本节的 zengl_lang_v0.0.8.exe 或者linux下的zengl 来编译test2.zl ,再用zenglrun来运行test2.zlc进行测试。
这条代码就涉及到了优先级的比较,编译器在调用parser.c中的buildAST函数组建语法树时,会循环调用statement函数来生成每个表达 式的AST语法树。在statement函数中当遇到本例的print关键字时就会调用print_stmt函数来专门生成print表达式的语法树。在 print_stmt函数里,就会调用express2函数先生成 'a is ' + a = 5 + 8 * 7 / 3 - 2 的AST,再将该AST的顶部节点加入到print节点的子节点中。
我们主要来看下 'a is ' + a = 5 + 8 * 7 / 3 - 2 这个表达式的AST的生成情况,也就是express2函数的执行过程。
首先,'a is ' 字符串遇到加法运算符‘+’时,会无条件的成为加法运算符第一个子节点:
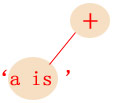
当加法遇到a标示符时,他并不会马上就将a标示符收服为他的第二个弟子,因为他需要看看他的竞争对手到底比他强还是比他弱,他会和a标示符右边的赋值运算 符进行优先级的比较,由于赋值运算符在中间时具有最高的优先级,所以a标示符将会成为赋值运算符的子节点,而加法运算符则会进入堆栈中,等待下一次的优先 级比较:
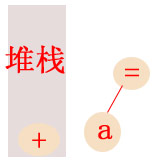
赋值运算符会在递归的express2函数里生成随后的子表达式的AST,在递归的express2函数中,赋值运算符作为第一个赋值运算符时优先级是最 低的,所以赋值运算符会和前面的加法运算符一样进入堆栈中,并递归进入express2函数来生成子表达式5 + 8 * 7 / 3 - 2的AST,在该层递归express2函数中,5会成为加法的子节点,但是当加法遇到8后面的乘法运算符时因为优先级低所以也进入堆栈,并再次递归 express2函数,因为乘除法有相同优先级,所以8和7会成为乘法的子节点,而乘法将成为除法的子节点,之后除法会遇到减法运算符,减法运算符的优先 级比除法低,这时就需要将减法运算符和堆栈里的运算符进行优先级的比较,来决定除法节点所在的express2函数是直接返回,还是成为减法的子节点(如 果你有点晕,就看下图):
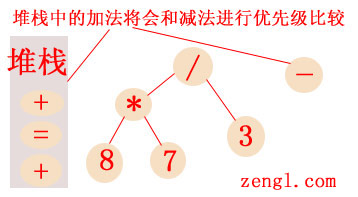
因为加法和减法具有相同优先级,根据从左到右的法则,除法节点所在的递归express2函数将会返回,并且返回的顶部节点除法运算符将成为+加法节点的子节点,同时将加法从堆栈中恢复出来:
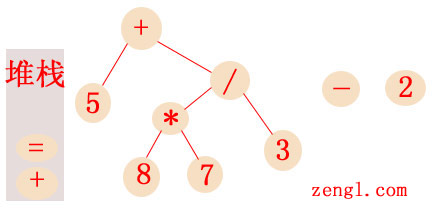
然后顶部的加法节点会成为减法的子节点,最后一个数字2因为没有其他的竞争对手了,所以也会成为减法的子节点。接着递归express2函数会返回,将堆栈中的赋值运算符恢复出来,并将返回的减法节点作为赋值节点的子节点:
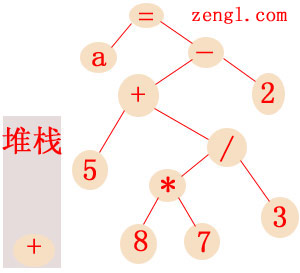
赋值节点AST生成完后,第二层递归的express2函数就会返回,将堆栈中的最后一个加法节点恢复出来,并将返回的赋值节点作为加法的子节点:
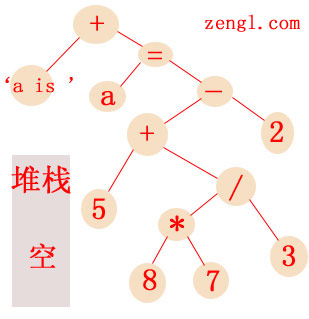
最后顶层express2函数返回,在print_stmt函数里,返回的顶部加法节点作为print节点的子节点,最终生成的语法树为:
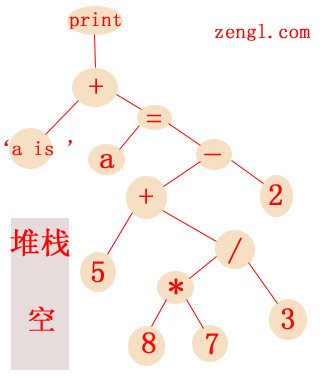
OK ,语法树的解析过程就讲到这,应该不会晕了O(∩_∩)O~。
最后说下编译代码的注意事项:
对于其他代码的分析,因为已经在C源代码里加了很多注释,请结合注释,加上VS2008之类的调试开发环境进行调试分析。
对于windows用户,请确保在项目属性的配置里,命令参数配置的是test.zl(对于zengl_lang_v0.0.8的项目)或test.zlc(对于zenglrun的项目),上一节提到过。
linux系统下的用户请结合usage.txt的说明,先运行make clean 将原来生成的zengl zenglrun 和 main.o parser.o assemble.o func.o run.o symbol.o文件删除。
再运行make all (单纯的make只能生成zengl,所以需要make all来生成所有的目标)
生成zengl zenglrun 和 main.o parser.o assemble.o func.o run.o symbol.o。(在生成过程中如果出现一些警告,暂不管他)
最后运行 ./zengl test.zl 查看printASTnodes函数打印抽象语法树节点的结果,以及符号表输出的变量信息(例如变量的内存地址,以及在源文件的行列号等)。
接着运行./zenglrun test.zlc (注意是.zlc结尾的文件名,因为zenglrun虚拟机只能运行.zlc里的汇编代码)。
本例的抽象语法树等很多高级的原理都可以在《龙书》中找到。
最后的最后,如果转载请注明来源 http://www.zengl.com , OK , 先到这里,休息,休息一下 O(∩_∩)O~