zengl编程语言v0.0.3构建抽象语法树
zenglong 2012-10-21 10:07:48
上一节完成了初始化抽象语法树的工作,这一节将会使用初始化抽象语法树里存放的节点信息构建一个可以表达单条语句的语法树。 本节v0.0.3版本的代码下载地址:http://sourceforge.net/projects/...
上一节完成了初始化抽象语法树的工作,这一节将会使用初始化抽象语法树里存放的节点信息构建一个可以表达单条语句的语法树。
本节v0.0.3版本的代码下载地址:http://sourceforge.net/projects/zengl/files/zengl_lang_v0.0.3_forXP.rar/download (此为XP版本的sourceforge上的下载地址),http://sourceforge.net/projects/zengl/files/zengl_language_v0.0.3_forLinux.tar.gz/download (此为linux版本的sourceforge上的下载地址)。http://sourceforge.net/projects/zengl/files/v0.0.3-v0.0.2-diffs.txt/download (此为v0.0.3和v0.0.2版本的代码变化情况)。
百度盘的共享链接地址:http://pan.baidu.com/share/link?shareid=85548&uk=940392313
本节的代码文件和上一节一样,还是三个文件,先来看下main.c源代码的变化:在main.c的开头增加了reserves字 符串数组。里面存放的都是zengl编程语言的关键字,例如 if ,else ,for之类的在程序里有特殊含义的标示符,普通的标示符名是不可以使用这些关键字的。这里暂时只存放了print关键字,这个关键字就和python里 的print一样是用来打印字符串信息用的。 main.c里的lookupReserve函数就是通过一个循环来判断一个token信息是否在reserves数组里,如果在数组里就将token设为RESERVE枚举值,表示该token是一个关键字。
在main.c文件的getToken函数的while循环里增加了一个startStr_ch局 部变量,当扫描器遇到一个单引号字符或者双引号字符时,就表示扫描到了一个字符串信息,然后将单引号或双引号存放到startStr_ch变量里,当再次 碰到startStr_ch里存放的字符时(该字符可以是单引号或双引号),表示一个字符串结束。这样就可以扫描出一个字符串的Token了。例如 print 'hello world' 这段代码,扫描器会先扫描出print这个ID标示符,然后根据程式if(token == ID) token = lookupReserve(token); 将print转为关键字,接着扫描器根据开始的单引号和结束的单引号来扫描出一个字符串hello world 。这样print关键字就可以根据后面扫描出的hello world字符串将该信息打印出来。另外在getToken函数里还增加了左括号和右括号的Token扫描,左右括号的作用和c语言里的左右括号一样,当表达式里出现括号时,括号里的表达式优先执行。最后还增加了一个分号的扫描,分号的作用也和C语言,PHP语言里分号的作用一样,表示一条表达式结束,当扫描完一条表达式后,扫描器就会调用parser语法分析器里的buildAST函数来构建该条表达式的AST抽象语法树。
OK,来看下本节里最重要的parser.c语法分析器的代码。语法分析器就是用来构建抽象语法树的程式。
在parser.c里的buildAST函数会调用express()函数来生成单条表达式的AST(抽象语法树英文缩写)。express函数也是采用和扫描器一样的state状态机的方法来构建语法树。来看下express函数的代码:
int express()
{
Node_Type *nodes = AST_nodes.nodes; //抽象语法树的节点数组,存放了所有保存的token节点信息。
int state = START; //先将state状态设为START,表示开始状态
int p=-1; //语法树是一个父子关系图,所以用p来表示父节点。
bool IsMidTim_Div = FALSE; //判断乘除运算符是否在中间,在中间时会有个优先级的判断处理,tim是times乘以的英文缩写,div是除以的英文缩写。
int tmpnode = -1; //执行程式里用于存放节点信息的临时变量。tmp是temporary临时的英文缩写
while(state!=DOWN) //当state状态机变为DOWN状态时表示一个表达式的AST构建完成,并返回该AST的最顶端的父节点。
{
curnode++; //curnode是前面定义过的一个全局变量,该变量是当前要分析的节点的数组索引,cur是current 当前的英文缩写。每次循环的开头都对curnode进行加一的操作,这样就可以分析下一个节点。
switch(state) //通过switch...case结构来判断state状态机要执行的程式。
{
case START:
if(ISTOKTYPE(ID)) //ISTOKTYPE是在global.h里定义的一个宏,用来判断当前节点的token类型是否是一个ID标示符。
{
p = curnode; //如果是标示符,就将当前节点设为父节点,并将state设为INID 状态机的枚举值。下一次循环switch case时就会进入INID的程式。
state = INID;
}
else if(ISTOKTYPEOR(TIMES,DIVIDE)) //ISTOKTYPEOR也是global.h里定义的宏,可以带两个参数,如果当前节点curnode是乘或除运算符,就将IsMidTim_Div设为TRUE,再设置父节点和state状态机。
{
IsMidTim_Div = TRUE;
p = curnode;
state = INTIME_DIVIDE;
}
else if(ISTOKTYPE(LBRACKET))
{
if(ISTOKTYPEXOR(curnode+1,ID,LBRACKET)) //如果当前节点是左括号,且左括号后面的节点是标示符或者左括号,就先将括号里的表达式生成AST。
{
tmpnode = curnode;
p = express(); //将括号里的表达式生成AST,并返回该AST的父节点
if(!ISTOKTYPE(RBRACKET)) //每个左括号都对应一个右括号,否则产生语法错误
myexit("syntax error start no right bracket"); //语法错误:没有右括号的英文提示。
else if(ISTOKTYPEXOR(tmpnode-1,ASSIGN,LBRACKET)) //如果左括号的左边是赋值运算符或者左括号,就将括号表达式的AST的父节点当做ID标示符,并进入INID的程式处理,而不返回。
state = INID;
else //其他的情况下说明括号在中间,就返回。
state = DOWN;
}
else
myexit("syntax error left bracket"); //如果左括号的后面一个节点不是ID标示符也不是左括号,就产生语法错误。
}
else
myexit("syntax error start"); //其他情况下产生start状态的语法错误。
break;
case INID:
if(ISTOKTYPE(ASSIGN)) //当ID标示符遇到赋值运算符,就将标示符节点作为赋值运算符节点的子节点。并进入INASSIGN状态
{
AddNodeChild(curnode,p);
p = curnode;
state = INASSIGN;
}
else if(ISTOKTYPEOR(PLUS,MINIS)) //ID标示符遇到加减运算符时,加入到加减运算符的子节点。并进入INPLUS_MINIS状态。
{
AddNodeChild(curnode,p);
p = curnode;
state = INPLUS_MINIS;
}
else if(ISTOKTYPEOR(TIMES,DIVIDE)) //ID标示符遇到乘除运算符时,加入到乘除运算符的子节点。并进入INTIME_DIVIDE状态。
{
AddNodeChild(curnode,p);
p = curnode;
state = INTIME_DIVIDE;
}
else if(ISTOKTYPE(SEMI)) //遇到分号结束循环
state = DOWN;
else
myexit("syntax error inid"); //其他情况产生INID状态机语法错误。
break;
case INASSIGN:
curnode--;
AddNodeChild(p,express()); //在赋值运算中,先将赋值符右边的表达式构成AST,再将该AST返回的父节点作为赋值运算符节点的子节点。并返回
state = DOWN;
break;
case INPLUS_MINIS:
if(ISTOKTYPE(ID) && ISTOKTYPEXOR(curnode-1,PLUS,MINIS)) //加减运算符右边是ID标示符时,将ID加入运算符的子节点。
AddNodeChild(p,curnode);
else if(ISTOKTYPEOR(PLUS,MINIS) && ISTOKTYPEXOR(curnode-1,ID,RBRACKET)) //当加减运算符遇到同级的加减符号时,将前一个加减运算符作为后面的加减运算符的子节点,这样就会从左到右依次执行。
{
AddNodeChild(curnode,p);
p = curnode;
}
else if(ISTOKTYPEOR(TIMES,DIVIDE) && ISTOKTYPEXOR(curnode-1,ID,RBRACKET)) //加减遇到乘除法时,将加减符号后面的ID标示符节点转给乘除节点,因为乘除法优先级高,再将乘除法构成的AST的父节点作为加减符号的子节点。
{
AddNodeChild(curnode,RemoveLastChild(p));
curnode--;
AddNodeChild(p,express());
}
else if(ISTOKTYPE(LBRACKET) && ISTOKTYPEXOR(curnode-1,PLUS,MINIS)) //当加减遇到括号时,将括号里的表达式的AST作为加减的子节点。
{
curnode--;
AddNodeChild(p,express());
}
else if(ISTOKTYPEOR(SEMI,RBRACKET) && ISTOKTYPEXOR(curnode-1,ID,RBRACKET)) //当遇到分号或右括号时,state设为DOWN结束循环并返回。
state = DOWN;
else
myexit("syntax error inplus_minis"); //其他情况下产生INPLUS_MINIS状态机的语法错误。
break;
case INTIME_DIVIDE:
if(ISTOKTYPE(ID) && ISTOKTYPEXOR(curnode-1,TIMES,DIVIDE)) //乘除运算符遇到ID标示符时,将ID加入为乘除的子节点。
AddNodeChild(p,curnode);
else if(ISTOKTYPEOR(TIMES,DIVIDE) && ISTOKTYPEXOR(curnode-1,ID,RBRACKET)) //遇到同级的乘除时,前面的乘除节点作为后面乘除节点的子节点。并将后面的乘除节点作为父节点继续后面的AST生成。
{
AddNodeChild(curnode,p);
p = curnode;
}
else if(ISTOKTYPEOR(PLUS,MINIS) && ISTOKTYPEXOR(curnode-1,ID,RBRACKET))
{
if(IsMidTim_Div) //当遇到加减时,如果乘除位于中间,说明乘除之前还有个等待递归返回的加减节点,就结束循环并返回。
{
curnode--;
state = DOWN;
}
else
{
AddNodeChild(curnode,p); //乘除位于开头则不需返回,直接加入后面加减的子节点中。
p = curnode;
state = INPLUS_MINIS;
}
}
else if(ISTOKTYPEOR(SEMI,RBRACKET) && ISTOKTYPEXOR(curnode-1,ID,RBRACKET)) //遇到分号或右括号时,结束循环并返回。
{
if(IsMidTim_Div)
curnode--;
state = DOWN;
}
else if(ISTOKTYPE(LBRACKET) && ISTOKTYPEXOR(curnode-1,TIMES,DIVIDE)) //遇到括号时,先express()递归生成括号里表达式的AST,再将该AST返回的顶端父节点作为自己的子节点。
{
curnode--;
AddNodeChild(p,express());
}
else
myexit("syntax error intime_divide"); //其他情况下产生INTIME_DIVIDE状态机的语法错误。
break;
default:
myexit("syntax error"); //switch... case 未知状态机的语法错误。
break;
}//switch
}//while
return p; //结束循环并返回当前express函数构建的AST的顶端父节点。
}
这个express函数可以说是整个zengl编程语言核心部分最复杂,最难理解的 部分,因为要考虑到实际表达式中各种可能的情况,正因如此,这种方法一旦要扩充更多的运算符,更多的表达方式时,就会显得很难入手,所以在后面的版本中会 采用一种更好的方式,虽然那种方式也比较复杂,不过比现在的这种方法更容易扩充更多的运算符,这个留到以后遇到的时候再说,先举个例子来说明该函数的执行 过程。
比如在本节代码文件里的test.zl中的测试代码:test = abc + money * id / unit - (max * num);
一开始state状态机为START状态时: 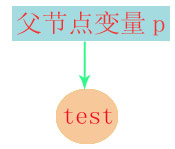 并进入INID状态。
并进入INID状态。
在INID状态时,遇到赋值符时: 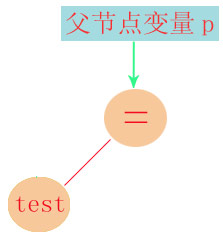 test标示符作为赋值运算符的子节点,并进入INASSIGN状态。
test标示符作为赋值运算符的子节点,并进入INASSIGN状态。
在INASSIGN时,先生成右边表达式的AST,即递归调用express函数。
在递归express函数里state状态机又从START状态开始: 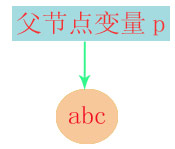 并进入INID状态。
并进入INID状态。
在INID状态遇到加法运算符时: 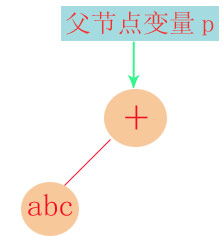 并进入INPLUS_MINIS状态。
并进入INPLUS_MINIS状态。
在INPLUS_MINIS状态时遇到money标示符: 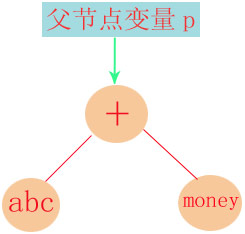
还是处于INPLUS_MINIS状态,遇到乘法运算符: 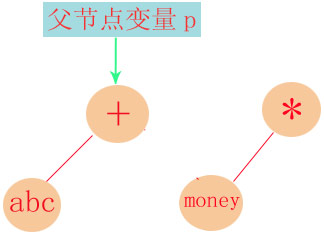
此时递归进入express函数来生成乘法及其后的节点构成的AST 。
在递归的express函数里state从START开始,因为在递归之前,curnode进行了减一操作,所以START时的curnode指向乘运算符。并进入INTIME_DIVIDE状态。
在INTIME_DIVIDE状态时,遇到id标示符: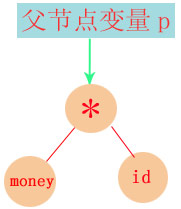
当遇到除号时: 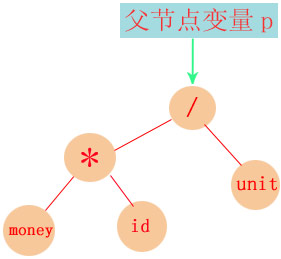
后面的过程以此类推,篇幅原因不多讲了,经过递归调用express函数,层层返回,最终合成的AST为:
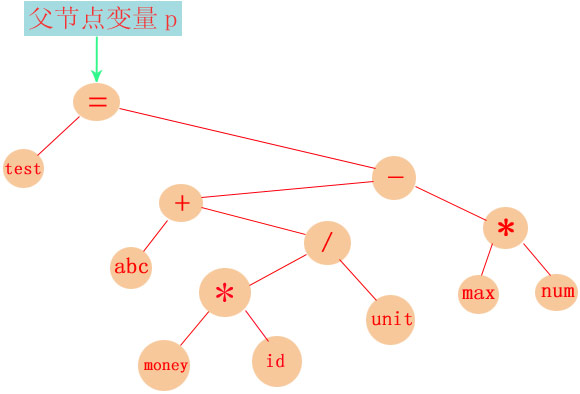
该例子就讲到这,其他函数的分析请自行研究源代码。
为了方便查看上个版本和当前版本的不同,所以从git提取了信息存放在v0.0.3-v0.0.2-diffs.txt文件里,从该文件里可以看出两个版本的代码变化情况。
v0.0.3-v0.0.2-diffs.txt的下载地址: http://sourceforge.net/projects/zengl/files/v0.0.3-v0.0.2-diffs.txt/download
最后linux下的用户在解压Linux版代码后,根据usage.txt的说明,先make clean 清理原来生成的二进制文件,再make生成当前环境下的可执行文件,最后./zengl test.zl 来测试,当然前提是安装了gcc编译器。
在./zengl test.zl测试时会打印输出详细的AST抽象语法树的组成详情,例如: 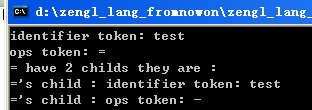
这里表示赋值运算符有两个子节点:一个是test标示符,一个是减法操作运算符。
本例的抽象语法树等很多高级的原理都可以在《龙书》中找到。
最后的最后,如果转载请注明来源 http://www.zengl.com , OK , 先到这里,休息,休息一下 O(∩_∩)O~