zengl编程语言v0.0.14加载模块函数
zenglong 2013-01-29 04:21:35
之前的版本中,比较有用的指令是print指令,用于打印输出字符串信息的,其实内部调用的是printf这个C库函数,但是如果每个外部功能比如一些常 规的win32 api之类的都做成指令的形式,一方面会...
之前的版本中,比较有用的指令是print指令,用于打印输出字符串信息的,其实内部调用的是printf这个C库函数,但是如果每个外部功能比如一些常 规的win32 api之类的都做成指令的形式,一方面会增加开发维护难度,另一方面也极不利于扩展新的功能,所以本节就引入模块的概念,将需要扩展的api之类的函数都 做到模块里,脚本里需要使用某个模块时,就通过use指令来加载模块,然后就可以直接调用模块里的各种api函数了。
本节v0.0.14版本的源代码下载地址为:http://pan.baidu.com/share/link?shareid=187545&uk=940392313 (此为百度云盘的共享链接地址),访问该地址可以看到三个文件:zengl_lang_v0.0.14_forXP.rar (XP系统下的vs2008解决方案和源代码), zengl_language_v0.0.14_forLinux.tar.gz (Linux系统下的源代码和makefile) ,v0.0.14-v0.0.13-diffs.txt (v0.0.14和v0.0.13的代码变化情况)。
SourceForge.net上的仓库地址为:https://sourceforge.net/projects/zengl/files/ 从里面可以看到各个版本的代码压缩包,比如本节的zengl_lang_v0.0.14_forXP.rar ,zengl_language_v0.0.14_forLinux.tar.gz,v0.0.14-v0.0.13-diffs.txt 。
先来看下本版本的描述 (在linux代码包里的usage.txt里有这段描述,在目前几个带有git版本的....-diffs.txt和git log中也有这段描述):
v0.0.14版本,该版本添加了use关键字,并增加了些内建函数,修复了递归调用导致的堆空间corrupt的BUG
在main.c中增加了use关键字的识别,parser.c中增加了对use的处理来生成use对应的语法树,在assemble.c中对应增加了 use的汇编输出,use会直接转为USE汇编指令,例如use builtin;对应汇编指令为USE "builtin"。
在run执行时,会调用builtin.c模块中的fun_builtin_init方法将builtin模块中的函数添加到fun函数的hash表中, 这样在汇编代码中使用call 调用这些函数时,就会在hash表中查找函数名,并转为函数对应的enum枚举值,并作为参数传递给builtin模块中的 fun_builtin_call函数,来执行具体的函数代码。
这样zengl编程语言就可以调用外部模块中的函数了,builtin里将会加入些常用的函数,还可以添加像SDL之类的模块来调用SDL游戏引擎中的函 数,或者添加些gtk或wxwidget之类的模块来调用相应的GUI函数来生成GUI图形窗口。在目前的builtin模块中已经添加了printf和 read函数,printf函数和print关键字的区别在于,printf不会在最后添加回车符,read函数可以读取用户在终端的输入。
在原来的版本中parser.c里的printNode函数采用的是递归方法来打印出语法树的结构,但是当代码量增大的情况下,或者每行代码变得复杂的情 况下,递归深度就会很大,可能就会栈溢出而导致堆空间的corrupt的BUG,我还不清楚为何栈会导致堆被破坏,至少,实际执行时确实出现了这个问题, 所以该版本就采用了非递归法来代替递归函数调用。
在该非递归法中,增加了一个gl_TreeStack的模拟栈,用于将循环中的当前节点或子节点或next节点压入栈,这样在处理完子节点并弹出子节点时,可以继续当前节点的处理,这样就可以利用循环和模拟栈完成整个语法树的扫描。
另外在symbol.c中的ScanFunArg_Global_Use函数(用于扫描fun函数的参数及扫描global,use关键字的子节点)和 ScanFunLocal函数(用于扫描fun函数里的局部变量),这两个函数中因为要扫描语法树的函数部分的节点信息,所以也利用循环和 parser.c中的模拟栈来代替以前的递归算法。
实际测试结果也证明了这一方法的正确性,另外非递归法可以提高执行的性能。
在makefile文件中为zenglrun添加了builtin.o模块,以及builtin.c模块的编译部分。
作者:zenglong
时间:2012年3月25日
官方网站:www.zengl.com
具体的C文件代码部分,请结合源代码中的注释,加上git工具以及vs2008或者eclipse+CDT或者gcc,gdb等工具进行分析。
下面通过本节的test.zl测试脚本的例子来说明(下面的注释仅在此起说明作用,原文件中并没有,因为注释的功能要在后面的版本中才实现):
use builtin; //通过use语句加载builtin内建模块。
print 'IQ机器人: 走自己的路让别人说吧的名句是出自何人的诗?';
answer = ""; //通过将空字符串赋值给answer,将answer的运行时类型从默认的整数类型转为字符串类型,这样才能进行下面的answer和'exit'字符 串的比较工作。否则当整数和字符串进行直接比较时,会得到相反的结果,大家可以试下,原因是整数和字符串进行比较时,字符串会通过atoi转为整 数,exit字符串转为整数就是0,而answer默认值也是0,所以就会得到answer等于exit字符串的结果,和我们要的结果相反。
for(null; answer!='exit' && score!=100; null) //这里之所以在for里加入null变量,null是随便起的变量名,是因为目前的for结构还不太完善,如果没有null这类的表达式摆在这的话,就会报编译错误,在以后的版本中会处理这个问题,本节就先暂时这么处理。
score = 0;
printf("请在此输入答案:"); //通过printf内建模块函数打印信息。
answer = read(); //通过read内建模块函数来读取用户的输入数据。
if(answer == '阿利盖利 但丁')
printf("答对了!");
score = 100;
print '分数:' + score; //可以和printf内建模块函数进行比较。
elif(answer == '但丁' || answer == '阿利盖利')
printf("答对了一半!");
score = 50;
print '分数:' + score;
elif(answer != 'exit')
print '答错了!分数:' + score;
endif
endfor //这段代码会循环要求用户输入答案,直到输入完全正确,或者输入exit才退出循环结束程序。
test.zl生成的test.zlc汇编文件因篇幅限制,这里只显示和本节相关的部分(下面的注释仅在此起说明作用):
0 USE "builtin"; //use语句会转为USE汇编指令
1 print "IQ机器人: 走自己的路让别人说吧的名句是出自何人的诗?";
2 MOV AX "";
3 MOV (1) AX;
4 MOV AX (1);
.................... //省略N行代码
17 PUSH ARG; //调用模块函数的开始部分和普通的函数调用一样。
18 PUSH LOC;
19 RESET ARGTMP;
20 MOV AX "请在此输入答案:";
21 PUSH AX; //参数压入栈
22 PUSH 26; //返回地址压入栈
23 MOV ARG ARGTMP; //设置ARG参数寄存器
24 RESET LOC; //设置LOC局部变量寄存器
25 CALL "printf"; //通过CALL指令来调用printf内建模块函数,普通的用户自定义的函数调用是通过JMP指令跳转到目标汇编代码处的。
26 PUSH ARG; //和上同理
27 PUSH LOC;
28 RESET ARGTMP;
29 PUSH 33;
30 MOV ARG ARGTMP;
31 RESET LOC;
32 CALL "read"; //通过CALL指令来调用read内建模块函数
................ // 省略N行代码。
下 面是在windows XP下的cmd命令行提示符下的脚本运行的截图,linux系统下的结果也差不多,不过linux下在终端输入汉字时,如果中间退过格就容易得不到想要的 结果,还会影响下一次的答案输入,这种情况下可以多退几次格,把之前的输入缓存里的回车退格之类的都清理掉,再输入,确保一次输入正确,中间不要有退格之 类的,就不会出现问题,如果Linux终端还不支持汉字的话,可以把test.zl测试脚本里的汉字全部用相同含义的英文来代替,英文字符就肯定不会有问 题了。
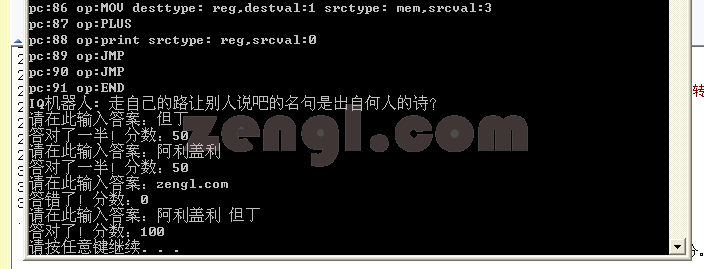
上面就是use加载模块,和模块函数的使用的相关细节。下面来看下本节最重要的部分,AST语法树扫描部分。
本节采用模拟堆栈加循环的非递归法来代替之前的递归函数调用方法, 进行语法树的扫描。语法树的扫描主要用于parser.c语法解析文件的printASTnodes函数(用于打印所有的AST语法树的节点信息的函 数),以及symbol.c文件里的ScanFunArg_Global_Use函数(用于扫描语法树中函数的参数,global引用的全局变量,use 加载的模块) 和ScanFunLocal函数(用于扫描语法树中函数的局部变量)。
下面是printASTnodes函数的C源代码:
/*
打印出AST抽象语法树的所有节点信息。采用了新的AST扫描堆栈的方法进行遍历扫描。
*/
void printASTnodes()
{
TREE_STACK_TYPE tmpstack;
Node_Type * nodes = AST_nodes.nodes;
int nodenum;
push_TreeStack(AST_nodes.rootnode); //将AST根节点压入栈,表示从根节点开始,将AST里的所有节点信息全部遍历打印输出。
do{
tmpstack = pop_TreeStack(FALSE); //返回前面压入栈的节点信息。参数FALSE表示只返回信息,暂不将节点从堆栈中删除。
if(tmpstack.curchild == 0) //curchild表示当前正在扫描的子节点索引,0表示还没开始扫描子节点,就将当前节点信息打印输出。
printNode(tmpstack.nodenum);
if(tmpstack.childcnt > 0) //如果返回的节点里包含子节点,则将子节点信息打印出来。
{
if(tmpstack.curchild < tmpstack.childcnt) //当curchild小于childcnt子节点数时,说明子节点还没全部打印完,就继续打印其他的子节点信息。
{
if(tmpstack.curchild == 0) //先显示当前节点一共有多少个子节点。
printf("(%d) %s has %d childs: \n",tmpstack.nodenum,
get_token_str(nodes,tmpstack.nodenum),tmpstack.childcnt);
if(tmpstack.curchild < NODECHILD_SIZE) //如果小于NODECHILD_SIZE,就将childnum里的基本子节点信息打印出来,否则就将extchilds扩展子节点里的节点信息打印出来。
nodenum = nodes[tmpstack.nodenum].childs.childnum[tmpstack.curchild];
else
nodenum = nodes[tmpstack.nodenum].childs.extchilds[tmpstack.curchild -
NODECHILD_SIZE];
printf("(%d) %s (%d) child is ",tmpstack.nodenum,
get_token_str(nodes,tmpstack.nodenum),tmpstack.curchild);
gl_TreeStack.stacks[gl_TreeStack.count - 1].curchild++; //将当前扫描的节点索引加一,这样下次就可以扫描下一个子节点。
push_TreeStack(nodenum); //将当前扫描的子节点压入栈,这样就和之前压入栈的节点在堆栈中构成了一个节点路径。
continue; //continue后会跳到do...while开头,然后pop_TreeStack和printNode就会将刚压入栈的子节点信息打印出来。
}
else
printf("(%d) %s childs end \n",tmpstack.nodenum,
get_token_str(nodes,tmpstack.nodenum),tmpstack.childcnt); //子节点扫描完毕。
}
if(tmpstack.next != 0) //如果当前节点有next兄弟节点,就将当前节点弹出,并将next节点压入栈
{
printf("(%d) %s has nextnode: ",tmpstack.nodenum,
get_token_str(nodes,tmpstack.nodenum));
pop_TreeStack(TRUE);
push_TreeStack(tmpstack.next);
continue; //continue后会跳到do...while开头,然后pop_TreeStack和printNode就会将刚压入栈的next节点信息打印出来。
}
else
pop_TreeStack(TRUE); //当子节点和next节点信息都打印完了,就将节点从堆栈中弹出。
}while(gl_TreeStack.count > 0); //如果堆栈中还有元素,说明还有节点信息没打印完,只有当堆栈里的元素个数为0时则表示所有AST里的节点信息都打印完了,就可以跳出循环返回了。
}
上 面这段代码显示了利用模拟堆栈取代常规的递归调用的方法,递归调用虽 然简单但是递归调用过多会导致进程的开销过大,容易引发内存问题,模拟堆栈则可以很好的解决这个问题,这里显示的源代码和注释信息在源文件中也有,可以使 用vs2008,eclipse+CDT或gcc,gdb之类的工具调试分析。
其他更多的细节部分,请结合源代码,git log -p 和前面提到过的开发调试工具进行分析。
最后还是老生常谈的话题:
windowsXP压缩包中的代码包括test.zl测试脚本都是采用GBK的编码,Linux压缩包中的代码包括测试文件以及git里的信息都是UTF8的编码,所以如果哪些地方出现了乱码,请自行调整。
对于windows用户,请确保在项目属性的配置里,命令行参数配置的是test.zl(对于zengl_lang_v0.0.14的项目)或test.zlc(对于zenglrun的项目),好像每一节都提到过。
另外对于vs2008的用户,我在项目属性里:[配置属性>>>>C/C++ >>>> 高级] 部分设置了禁用特定警告:4013,4715,4996 ,这几个警告会显示一些某某函数是非安全的函数,或者函数没有返回值等,这里禁用掉,防止出现过多的警告。另外还有个警告是显示某某变量没被使用过的, 这个警告我没禁用,可以不用管它。我最开始是使用Linux系统开发的zengl ,在我的GCC下面并没有显示过这些讨厌的警告,所以就没处理,不过还好这些警告都无关痛痒,无需理会。
还有一个地方,是前面没有提到过的:VS2008项目中,在[配置属性>>>> C/C++ >>>> 预处理器] 部分都设置了预处理器定义的宏:OS_IN_WINDOWS ,因为源代码既要在WINDOWS下编译,又要在LINUX下编译,所以需要通过这个宏来告诉程序当前的环境是windows还是linux,在 windows下面,在程序结束时会执行system ("pause");这条语句(vs2008下为了能看到结果,需要暂停,否则就一闪而过,什么都看不到咯。) 而linux系统主要在bash终端下执行,不需要这条语句。
linux系统下的用户请结合usage.txt的说明,先运行make clean 将原来生成的zengl zenglrun 和 main.o parser.o assemble.o ld.o func.o run.o symbol.o builtin.o文件(本节多了个builtin.o内建模块)删除。
再运行make all (单纯的make只能生成zengl,所以需要make all来生成所有的目标)
生成zengl zenglrun 和 main.o parser.o assemble.o ld.o func.o run.o symbol.o builtin.o。(在生成过程中如果出现一些警告,暂不管他)
最后运行 ./zengl test.zl 查看printASTnodes函数打印抽象语法树节点的结果,以及符号表输出的变量信息以及函数信息等。(例如变量的内存地址,以及在源文件的行列号,函数的唯一标识ID等)。
接着运行./zenglrun test.zlc (注意是.zlc结尾的文件名,因为zenglrun虚拟机只能运行.zlc里的汇编代码)。
zengl语言涉及到的很多高级的编译原理都可以在《龙书》中找到。
最后的最后,如果转载请注明来源 http://www.zengl.com , OK , 先到这里,休息,休息一下 O(∩_∩)O~