汇编中使用文件 (三) 使用文件结束篇
zenglong 2014-07-03 13:11:18
上一篇文章的readtest3程式无法对同一个文件同时进行读写操作,如果你对readtest3程式的输入和输出文件都使用相同的文件名的话,就会发生如下情况...
本文由zengl.com站长对汇编教程英文版相应章节进行翻译得来。
汇编教程英文版的下载地址:点此进入原百度盘 , 点此进入Dropbox网盘 , 点此进入Google Drive (Dropbox与Google Drive里是Assembly_Language.pdf文档)
另外再附加一个英特尔英文手册的共享链接地址:
点此进入原百度盘, 点此进入Dropbox网盘 ,点此进入Google Drive (在某些例子中会用到,Dropbox与Google Drive里是intel_manual.pdf文档)
Dropbox与Google Drive可能需要通过代理访问。
本篇翻译对应汇编教程英文原著的第501页到第511页,目前翻译完前16章 (注意这里的页数不是页脚的页数,而是pdf电子档顶部,分页输入框中的页数,也就是包含了目录,前言部分的总页数,pdf电子档总页数是577,当前已翻译完的页数为511 / 577)。
Memory-Mapped Files 内存映射文件:
上一篇文章的readtest3程式无法对同一个文件同时进行读写操作,如果你对readtest3程式的输入和输出文件都使用相同的文件名的话,就会发生如下情况:
上面的readtest3程式的输入和输出文件都指定的cpuid.txt,虽然 echo $? 命令显示的退出码为0,即没有错误发生,但是 cat cpuid.txt 命令显示cpuid.txt的内容全都丢失了,也就是说readtest3程式的代码无法对相同的文件既进行读操作,又进行写操作。
如果要对文件同时进行读写操作的话,其实有多种方法,其中一种就是下面要介绍的内存映射文件的方法。
What are memory-mapped files? 什么是内存映射文件?
当我们使用open系统调用打开文件后,系统会在内存里建立一个缓冲区域,然后将文件的内容放置在该缓冲区域里,但是open系统调用返回的是一个文件描述符,因此,我们无法像操作普通的内存数据一样直接对这段缓冲区域进行读写操作,必须使用read或write之类的系统调用来间接的对文件的缓冲区域进行读或写的操作,操作完后,还需通过close系统调用才能将缓冲区域里修改过的内容写回到磁盘里。
而通过内存映射的方式,就可以将文件映射到某段内存中,接着在程序里,就可以直接对这段内存进行读写操作了,当对这段内存操作完后,还可以将内存里的数据写回文件。
可以看出来,使用内存映射的方式来读写文件,避免了read及write系统调用的I/O开销,因此执行效率就比较高。
由于在映射的内存里,可以对文件内容同时进行读和写的操作(像操作普通的内存数据一样),这样也就解决了上面所提到的对同一个文件同时进行读写操作的问题。
此外,通过内存映射的方式,还可以将文件内容映射到一段共享内存中,这样多个进程就可以同时对这段内存里的文件数据进行读写操作了,如下图所示:
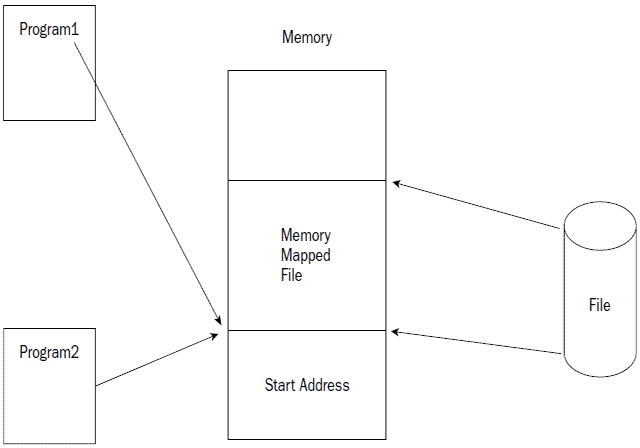
图1
上图显示当File文件被映射到内存的Start Address开始的共享区段后,Program1与Program2两个进程就都可以对这段内存里的文件数据进行读写操作了。
The mmap system call -- mmap系统调用:
我们可以使用mmap系统调用来创建内存映射文件,该系统调用的格式如下:
从上面的man 2 mmap命令的输出可以看到,该系统调用一共需要如下6个输入参数:
如果offset的值为0,且length的值为文件的尺寸大小,则整个文件都会被映射到内存中。
此外,mmap功能在很大程度上依赖于系统的内存页面大小(在32位系统下,页面大小通常是4096字节),如果length的值不能填满完整的页面的话,那么页面的剩余部分将被0填充,而且,如果要使用offset偏移值的话,那么offset的值必须是内存页面大小的倍数。
prot参数包含了对内存映射文件的访问权限,可用的值如下表所示:
flags参数用于指定所创建的内存映射对象是什么类型的,有如下两种类型:
上表中,MAP_SHARE类型的映射文件位于共享内存区域,当某个进程对这段内存区域进行修改后,其他使用该映射文件的进程也可以看到修改的情况。此外,该类型的内存映射里的内容被修改后,可以通过msync和munmap系统调用将修改的内容给写回原文件。
至于MAP_PRIVATE类型的映射文件则会位于写时复制的内存页面,当进程对这些页面进行写入操作时,会触发写时复制,这样所有的修改就只会对当前的进程可见了,而且,对这种类型的映射文件的修改不能写回原文件,在程序结束时这些修改都会被丢弃掉,这看起来有点古怪,但是,当你需要创建一个能够被快速访问的临时文件时,这种类型的内存映射文件就可以派上用场了。
上面提到,当对MAP_SHARE类型的映射文件进行修改后,如果要让修改能够及时的写回原文件的话,就需要使用msync或munmap的系统调用,这两个系统调用的含义如下:
msync与munmap系统调用的格式如下:
这两个格式同样可以在Linux命令行下,通过man 2 msync与man 2 munmap命令来查看到,这两个系统调用的前两个输入参数是一样的,第一个addr参数表示内存映射文件的起始线性地址,该地址可以通过之前的mmap系统调用的返回值来得到,length参数则表示需要同步到原文件的字节数,至于msync的最后一个flags参数则表示需要使用什么方式来更新原文件,有如下两种方式:
mmap assembly language format -- mmap在汇编中的格式:
要在汇编中使用mmap系统调用,首先就要知道mmap的系统调用号,在之前的"汇编里使用Linux系统调用 (二)"的文章中,我们介绍过,可以从 /usr/include/asm/unistd.h 的头文件(或者该文件所加载的其他头文件)中,找到所需的系统调用的调用号:
可以看到,在我的系统里,unistd.h头文件在32位系统中会去再加载unistd_32.h头文件,在该头文件里,就可以看到mmap的系统调用号为90,munmap的调用号为91,msync的系统调用号为144 。
因此,在汇编里要使用mmap系统调用的话,就需要将它的调用号90设置到EAX寄存器,再设置好相关输入参数即可。
在设置mmap系统调用的输入参数时,有一点需要注意的是,前面我们提到过,mmap有6个输入参数,在之前"汇编里使用Linux系统调用 (二)"的文章里说过,如果系统调用所需的输入参数超过5个时,可以将输入参数按顺序存储到某个内存位置或者内存栈里,然后将该内存位置的指针值存储到EBX寄存器,这样系统调用就会从EBX指向的内存位置里读取到所需的输入参数了。因此,要使用mmap系统调用的话,我们可以按照下图将6个输入参数依次放置到栈里,然后将栈顶指针赋值给EBX寄存器,再设置好EAX里的系统调用号,最后就可以执行mmap了:
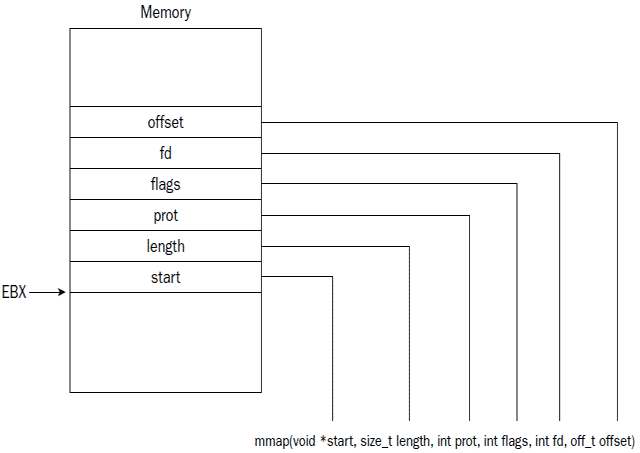
图2
在压入参数到栈里时,需要注意参数的压栈顺序,最先压入栈的对应最后一个参数,如上图里的offset参数,最后压入栈的对应第一个参数,如上图的start参数。此外,当执行完系统调用后,还需将栈里的这些参数给清理掉。
mmap系统调用的汇编模板如下所示:
上面的汇编模板用于创建包含某文件完整的内容的内存映射文件,并且该内存映射文件位于共享内存区域,进程可以对该内存区域的数据进行读写操作,由于是MAP_SHARED类型,因此,被修改的内存数据,可以通过msync或munmap系统调用给同步到原文件中。mmap系统调用的返回值存储在EAX寄存器里,用于指向内存映射文件的起始内存位置,我们可以将该内存位置存储到某个变量里,以供其他的系统调用使用。
至于munmap系统调用的汇编模板如下:
由于munmap系统调用只使用两个输入参数,因此,它们可以被分别放置在EBX和ECX里。另外,如果munmap系统调用返回0值,则表示该系统调用执行成功,即数据被成功写入到原文件里了。如果执行失败,则会返回-1值。
An mmap example 一个mmap的完整例子:
下面会通过一个完整的例子来演示如何通过mmap系统调用将文件的所有数据给映射到内存里,以及如何将内存里被修改的数据给写回到原文件。
Parts of the program 实际的代码部分:
要使用mmap将文件的所有内容都映射到内存中,就需要首先知道文件的尺寸大小信息,我们可以通过llseek系统调用来实现这点,该系统调用的格式如下:
从上面的DESCRIPTION描述信息里,可以看到,llseek系统调用一共有5个输入参数,第一个fd参数指向被打开的有效的文件描述符,第二个offset_high与第三个offset_low参数可以组成一个相对偏移值,组成方式为:(offset_high << 32) | offset_low ,这个偏移值是根据最后一个whence参数来进行偏移的,当whence为SEEK_SET时,则相对于文件开头进行偏移,当whence为SEEK_CUR时,则相对于当前的文件指针进行偏移,当whence为SEEK_END时,则相对于文件结束位置进行偏移,偏移操作后的文件指针的实际位置会被存储到result指向的内存里,如果我们要知道某个文件的尺寸大小信息,则可以将whence设置为SEEK_END,再将offset_high与offset_low都设置为0,这样文件指针就会被放置到文件的结束位置,result就可以存储到结束位置的值,这个值就是文件实际的尺寸大小(以字节为单位)。
另外,SEEK_END的常量值为2,下面的sizefunc.s文件就创建了一个sizefunc函数,该函数可以根据输入的文件描述符,返回对应文件的实际大小:
上面的sizefunc是一个C风格的汇编函数,C风格的汇编函数有一套标准的开场和结束代码,这方面的内容可以参考之前的"汇编函数的定义和使用 (二)"的文章。
在sizefunc代码里,会先将llseek的系统调用号140设置到EAX寄存器,再将8(%ebp)即输入的第一个参数作为文件描述符设置到EBX里,接着ECX与EDX都设置为0,也就是将llseek的offset_high与offset_low输入参数都设置为0,ESI寄存器里将-8(%ebp)作为result输入参数,-8(%ebp)相当于C语言函数中的局部变量,EDI中存储的2表示SEEK_END,最后通过int $0x80执行完llseek系统调用后,-8(%ebp)里就存储了文件实际的大小,再通过movl -8(%ebp), %eax指令就可以将文件大小作为返回值进行返回。
另外,-8(%ebp)对应的局部变量有8个字节,因为之前man 2 llseek命令的输出显示,result参数是loff_t类型,该类型是8个字节的大小,当然该函数最后以EAX返回时,只能将8个字节里的低4字节的数据进行返回。
有了sizefunc函数后,我们还需要一个convert函数,用于对映射到内存的文件数据进行读写操作,该函数的代码如下:
该函数也是一个C风格的汇编函数,该函数的作用和上一篇文章的readtest3.s程式里的convert函数一样(lodsb,stosb等指令的作用请参考上一篇文章),也是用于将输入参数指定的内存里的字符全部转为大写字母,只不过本章里,输入参数指定的内存位置为内存映射文件的位置,另外,本章的convert函数位于单独的convert.s文件里。
The main program 主程式:
现在,两个辅助函数都已经有了,下面的fileconvert.s程式就是主程式:
上面代码中红色标注的部分与英文原著不同,原著使用的是js badfile,但是mmap系统调用的返回值是一个指针值,当指针值为0xb7fff000的地址时,则js badfile就会误认为返回值是负数,也就会误跳转到badfile处,所以需要改为jz badfile,表示当返回值不为0时,就是一个有效的指针,否则就是无效的指针,才需要跳转到badfile处。
上面的代码按照以下6个步骤来完成相关的操作:
上面几个程式的编译运行结果如下:
可以看到,在运行 ./fileconvert cpuid.txt 后,cpuid.txt里的内容就都变为大写字母了。
我们还可以使用之前"汇编里使用Linux系统调用 (三) 系统调用结束篇"的文章的第2分页里提到的strace工具,来查看fileconvert程式所使用到的相关系统调用:
需要注意的是,strace工具是以C函数的形式来显示所使用过的系统调用的。
剩下是英文原著第16章的总结部分,限于篇幅,就不多说了。
下一篇开始介绍IA-32平台所提供的一些高级功能。
OK,就到这里,休息,休息一下 o(∩_∩)o~~
汇编教程英文版的下载地址:点此进入原百度盘 , 点此进入Dropbox网盘 , 点此进入Google Drive (Dropbox与Google Drive里是Assembly_Language.pdf文档)
另外再附加一个英特尔英文手册的共享链接地址:
点此进入原百度盘, 点此进入Dropbox网盘 ,点此进入Google Drive (在某些例子中会用到,Dropbox与Google Drive里是intel_manual.pdf文档)
Dropbox与Google Drive可能需要通过代理访问。
本篇翻译对应汇编教程英文原著的第501页到第511页,目前翻译完前16章 (注意这里的页数不是页脚的页数,而是pdf电子档顶部,分页输入框中的页数,也就是包含了目录,前言部分的总页数,pdf电子档总页数是577,当前已翻译完的页数为511 / 577)。
Memory-Mapped Files 内存映射文件:
上一篇文章的readtest3程式无法对同一个文件同时进行读写操作,如果你对readtest3程式的输入和输出文件都使用相同的文件名的话,就会发生如下情况:
$ ./readtest3 cpuid.txt cpuid.txt $ echo $? 0 $ cat cpuid.txt $ ls -l cpuid.txt -rw-r--r-- 1 root root 0 7月 1 20:04 cpuid.txt $ |
上面的readtest3程式的输入和输出文件都指定的cpuid.txt,虽然 echo $? 命令显示的退出码为0,即没有错误发生,但是 cat cpuid.txt 命令显示cpuid.txt的内容全都丢失了,也就是说readtest3程式的代码无法对相同的文件既进行读操作,又进行写操作。
如果要对文件同时进行读写操作的话,其实有多种方法,其中一种就是下面要介绍的内存映射文件的方法。
What are memory-mapped files? 什么是内存映射文件?
当我们使用open系统调用打开文件后,系统会在内存里建立一个缓冲区域,然后将文件的内容放置在该缓冲区域里,但是open系统调用返回的是一个文件描述符,因此,我们无法像操作普通的内存数据一样直接对这段缓冲区域进行读写操作,必须使用read或write之类的系统调用来间接的对文件的缓冲区域进行读或写的操作,操作完后,还需通过close系统调用才能将缓冲区域里修改过的内容写回到磁盘里。
而通过内存映射的方式,就可以将文件映射到某段内存中,接着在程序里,就可以直接对这段内存进行读写操作了,当对这段内存操作完后,还可以将内存里的数据写回文件。
可以看出来,使用内存映射的方式来读写文件,避免了read及write系统调用的I/O开销,因此执行效率就比较高。
由于在映射的内存里,可以对文件内容同时进行读和写的操作(像操作普通的内存数据一样),这样也就解决了上面所提到的对同一个文件同时进行读写操作的问题。
此外,通过内存映射的方式,还可以将文件内容映射到一段共享内存中,这样多个进程就可以同时对这段内存里的文件数据进行读写操作了,如下图所示:
图1
上图显示当File文件被映射到内存的Start Address开始的共享区段后,Program1与Program2两个进程就都可以对这段内存里的文件数据进行读写操作了。
The mmap system call -- mmap系统调用:
我们可以使用mmap系统调用来创建内存映射文件,该系统调用的格式如下:
$ man 2 mmap ............................................ void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); ............................................ $ |
从上面的man 2 mmap命令的输出可以看到,该系统调用一共需要如下6个输入参数:
-
start: Where in memory to map the file
start参数:将文件映射到虚拟内存的start所指向的线性地址处 -
length: The number of bytes to load into memory
length参数:需要被映射到内存里的字节数 -
prot: The memory protection settings
prot参数:内存的保护设置 -
flags: The type of mapped object to create
flags参数:要创建的映射对象的类型 -
fd: The file handle of the file to map to memory
fd参数:要被映射到内存的文件的描述符 -
offset: The starting point in the file to copy to memory
offset参数:将文件offset偏移处开始的数据给映射到内存
如果offset的值为0,且length的值为文件的尺寸大小,则整个文件都会被映射到内存中。
此外,mmap功能在很大程度上依赖于系统的内存页面大小(在32位系统下,页面大小通常是4096字节),如果length的值不能填满完整的页面的话,那么页面的剩余部分将被0填充,而且,如果要使用offset偏移值的话,那么offset的值必须是内存页面大小的倍数。
prot参数包含了对内存映射文件的访问权限,可用的值如下表所示:
|
Protection Name 保护名称 |
Value 常量值 |
Description 描述 |
|---|---|---|
| PROT_NONE | 0 | No data access is allowed. 不允许进行读写等相关的数据访问 |
| PROT_READ | 1 | Read access is allowed. 允许进行读操作 |
| PROT_WRITE | 2 | Write access is allowed. 允许进行写操作 |
| PROT_EXEC | 4 | Execute access is allowed. 内存映射里的数据可以作为指令来执行 |
flags参数用于指定所创建的内存映射对象是什么类型的,有如下两种类型:
|
Flag Name flag名称 |
Value 常量值 |
Description 描述 |
|---|---|---|
| MAP_SHARE | 1 |
Share changes to the memory-mapped file with other processes. 在共享的内存区段内创建映射文件,让多个进程可以共享这个内存映射文件,这样,所有的修改对每个进程而言都是可见的 |
| MAP_PRIVATE | 2 |
Keep all changes private to this process. 创建一个私有的写时复制的映射文件,进程对这段映射的修改会触发写时复制,因此所有的修改只对当前进程可见 |
上表中,MAP_SHARE类型的映射文件位于共享内存区域,当某个进程对这段内存区域进行修改后,其他使用该映射文件的进程也可以看到修改的情况。此外,该类型的内存映射里的内容被修改后,可以通过msync和munmap系统调用将修改的内容给写回原文件。
至于MAP_PRIVATE类型的映射文件则会位于写时复制的内存页面,当进程对这些页面进行写入操作时,会触发写时复制,这样所有的修改就只会对当前的进程可见了,而且,对这种类型的映射文件的修改不能写回原文件,在程序结束时这些修改都会被丢弃掉,这看起来有点古怪,但是,当你需要创建一个能够被快速访问的临时文件时,这种类型的内存映射文件就可以派上用场了。
上面提到,当对MAP_SHARE类型的映射文件进行修改后,如果要让修改能够及时的写回原文件的话,就需要使用msync或munmap的系统调用,这两个系统调用的含义如下:
-
msync: Synchronizes the original file to the memory-mapped file
msync系统调用:将内存映射文件的内容同步到原文件 -
munmap: Removes the memory-mapped file from memory and writes any changes to the original file
munmap系统调用:将内存映射文件的所有改动的数据都写回原文件,同时移除内存映射文件
msync与munmap系统调用的格式如下:
int msync(void *addr, size_t length, int flags); int munmap(void *addr, size_t length); |
这两个格式同样可以在Linux命令行下,通过man 2 msync与man 2 munmap命令来查看到,这两个系统调用的前两个输入参数是一样的,第一个addr参数表示内存映射文件的起始线性地址,该地址可以通过之前的mmap系统调用的返回值来得到,length参数则表示需要同步到原文件的字节数,至于msync的最后一个flags参数则表示需要使用什么方式来更新原文件,有如下两种方式:
-
MS_ASYNC: Updates are scheduled for the next time the file is available for writing, and the system call returns.
MS_ASYNC(异步方式):系统调用会马上返回,更新操作会在稍候,文件可写的时候由系统在后台完成 -
MS_SYNC: The system call waits until the updates are made before returning to the calling program.
MS_SYNC(同步方式):系统调用会被阻塞,直到所有的改动都写回原文件才返回
mmap assembly language format -- mmap在汇编中的格式:
要在汇编中使用mmap系统调用,首先就要知道mmap的系统调用号,在之前的"汇编里使用Linux系统调用 (二)"的文章中,我们介绍过,可以从 /usr/include/asm/unistd.h 的头文件(或者该文件所加载的其他头文件)中,找到所需的系统调用的调用号:
$ cat /usr/include/asm/unistd.h # ifdef __i386__ # include "unistd_32.h" # else # include "unistd_64.h" # endif $ cat /usr/include/asm/unistd_32.h #ifndef _ASM_X86_UNISTD_32_H #define _ASM_X86_UNISTD_32_H /* * This file contains the system call numbers. */ .................................................. .................................................. #define __NR_mmap 90 #define __NR_munmap 91 .................................................. #define __NR_msync 144 .................................................. .................................................. #endif /* _ASM_X86_UNISTD_32_H */ $ |
可以看到,在我的系统里,unistd.h头文件在32位系统中会去再加载unistd_32.h头文件,在该头文件里,就可以看到mmap的系统调用号为90,munmap的调用号为91,msync的系统调用号为144 。
因此,在汇编里要使用mmap系统调用的话,就需要将它的调用号90设置到EAX寄存器,再设置好相关输入参数即可。
在设置mmap系统调用的输入参数时,有一点需要注意的是,前面我们提到过,mmap有6个输入参数,在之前"汇编里使用Linux系统调用 (二)"的文章里说过,如果系统调用所需的输入参数超过5个时,可以将输入参数按顺序存储到某个内存位置或者内存栈里,然后将该内存位置的指针值存储到EBX寄存器,这样系统调用就会从EBX指向的内存位置里读取到所需的输入参数了。因此,要使用mmap系统调用的话,我们可以按照下图将6个输入参数依次放置到栈里,然后将栈顶指针赋值给EBX寄存器,再设置好EAX里的系统调用号,最后就可以执行mmap了:
图2
在压入参数到栈里时,需要注意参数的压栈顺序,最先压入栈的对应最后一个参数,如上图里的offset参数,最后压入栈的对应第一个参数,如上图的start参数。此外,当执行完系统调用后,还需将栈里的这些参数给清理掉。
mmap系统调用的汇编模板如下所示:
pushl $0 # offset of 0 pushl filehandle # the file handle of the open file pushl $1 # MAP_SHARED flag set to write changed data back to file pushl $3 # PROT_READ and PROT_WRITE permissions pushl size # the size of the entire file pushl $0 # Allow the system to select the location in memory to start movl %esp, %ebx # copy the parameters location to EBX movl $90, %eax # set the system call value int $0x80 addl $24, %esp movl %eax, mappedfile # store the memory location of the memory mapped file |
上面的汇编模板用于创建包含某文件完整的内容的内存映射文件,并且该内存映射文件位于共享内存区域,进程可以对该内存区域的数据进行读写操作,由于是MAP_SHARED类型,因此,被修改的内存数据,可以通过msync或munmap系统调用给同步到原文件中。mmap系统调用的返回值存储在EAX寄存器里,用于指向内存映射文件的起始内存位置,我们可以将该内存位置存储到某个变量里,以供其他的系统调用使用。
至于munmap系统调用的汇编模板如下:
movl $91, %eax movl mappedfile, %ebx movl size, %ecx int $0x80 |
由于munmap系统调用只使用两个输入参数,因此,它们可以被分别放置在EBX和ECX里。另外,如果munmap系统调用返回0值,则表示该系统调用执行成功,即数据被成功写入到原文件里了。如果执行失败,则会返回-1值。
An mmap example 一个mmap的完整例子:
下面会通过一个完整的例子来演示如何通过mmap系统调用将文件的所有数据给映射到内存里,以及如何将内存里被修改的数据给写回到原文件。
Parts of the program 实际的代码部分:
要使用mmap将文件的所有内容都映射到内存中,就需要首先知道文件的尺寸大小信息,我们可以通过llseek系统调用来实现这点,该系统调用的格式如下:
$ man 2 llseek ..................................................... int _llseek(unsigned int fd, unsigned long offset_high, unsigned long offset_low, loff_t *result, unsigned int whence); DESCRIPTION The _llseek() function repositions the offset of the open file associ‐ ated with the file descriptor fd to (offset_high<<32) | offset_low bytes relative to the beginning of the file, the current position in the file, or the end of the file, depending on whether whence is SEEK_SET, SEEK_CUR, or SEEK_END, respectively. It returns the result‐ ing file position in the argument result. ..................................................... $ |
从上面的DESCRIPTION描述信息里,可以看到,llseek系统调用一共有5个输入参数,第一个fd参数指向被打开的有效的文件描述符,第二个offset_high与第三个offset_low参数可以组成一个相对偏移值,组成方式为:(offset_high << 32) | offset_low ,这个偏移值是根据最后一个whence参数来进行偏移的,当whence为SEEK_SET时,则相对于文件开头进行偏移,当whence为SEEK_CUR时,则相对于当前的文件指针进行偏移,当whence为SEEK_END时,则相对于文件结束位置进行偏移,偏移操作后的文件指针的实际位置会被存储到result指向的内存里,如果我们要知道某个文件的尺寸大小信息,则可以将whence设置为SEEK_END,再将offset_high与offset_low都设置为0,这样文件指针就会被放置到文件的结束位置,result就可以存储到结束位置的值,这个值就是文件实际的尺寸大小(以字节为单位)。
另外,SEEK_END的常量值为2,下面的sizefunc.s文件就创建了一个sizefunc函数,该函数可以根据输入的文件描述符,返回对应文件的实际大小:
# sizefunc.s - Find the size of a file
.section .text
.globl sizefunc
.type sizefunc, @function
sizefunc:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
pushl %edi
pushl %esi
pushl %ebx
movl $140, %eax
movl 8(%ebp), %ebx
movl $0, %ecx
movl $0, %edx
leal -8(%ebp), %esi
movl $2, %edi
int $0x80
movl -8(%ebp), %eax
popl %ebx
popl %esi
popl %edi
movl %ebp, %esp
popl %ebp
ret
|
上面的sizefunc是一个C风格的汇编函数,C风格的汇编函数有一套标准的开场和结束代码,这方面的内容可以参考之前的"汇编函数的定义和使用 (二)"的文章。
在sizefunc代码里,会先将llseek的系统调用号140设置到EAX寄存器,再将8(%ebp)即输入的第一个参数作为文件描述符设置到EBX里,接着ECX与EDX都设置为0,也就是将llseek的offset_high与offset_low输入参数都设置为0,ESI寄存器里将-8(%ebp)作为result输入参数,-8(%ebp)相当于C语言函数中的局部变量,EDI中存储的2表示SEEK_END,最后通过int $0x80执行完llseek系统调用后,-8(%ebp)里就存储了文件实际的大小,再通过movl -8(%ebp), %eax指令就可以将文件大小作为返回值进行返回。
另外,-8(%ebp)对应的局部变量有8个字节,因为之前man 2 llseek命令的输出显示,result参数是loff_t类型,该类型是8个字节的大小,当然该函数最后以EAX返回时,只能将8个字节里的低4字节的数据进行返回。
有了sizefunc函数后,我们还需要一个convert函数,用于对映射到内存的文件数据进行读写操作,该函数的代码如下:
# convert.s - A function to convert lower case letters to upper case
.section .text
.type convert, @function
.globl convert
convert:
pushl %ebp
movl %esp, %ebp
pushl %esi
pushl %edi
movl 12(%ebp), %esi
movl %esi, %edi
movl 8(%ebp), %ecx
convert_loop:
lodsb
cmpb $0x61, %al
jl skip
cmpb $0x7a, %al
jg skip
subb $0x20, %al
skip:
stosb
loop convert_loop
pop %edi
pop %esi
movl %ebp, %esp
popl %ebp
ret
|
该函数也是一个C风格的汇编函数,该函数的作用和上一篇文章的readtest3.s程式里的convert函数一样(lodsb,stosb等指令的作用请参考上一篇文章),也是用于将输入参数指定的内存里的字符全部转为大写字母,只不过本章里,输入参数指定的内存位置为内存映射文件的位置,另外,本章的convert函数位于单独的convert.s文件里。
The main program 主程式:
现在,两个辅助函数都已经有了,下面的fileconvert.s程式就是主程式:
# fileconvert.s - Memory map a file and convert it .section .bss .lcomm filehandle, 4 .lcomm size, 4 .lcomm mappedfile, 4 .section .text .globl _start _start: # get the file name and open it in read/write mode movl %esp, %ebp movl $5, %eax movl 8(%ebp), %ebx movl $0102, %ecx movl $0644, %edx int $0x80 test %eax, %eax js badfile movl %eax, filehandle # find the size of the file pushl filehandle call sizefunc movl %eax, size addl $4, %esp # map file to memory pushl $0 pushl filehandle pushl $1 # MAP_SHARED pushl $3 # PROT_READ | PROT_WRITE pushl size # file size pushl $0 # NULL movl %esp, %ebx movl $90, %eax int $0x80 test %eax, %eax jz badfile movl %eax, mappedfile addl $24, %esp # convert the memory mapped file to all uppers pushl mappedfile pushl size call convert addl $8, %esp # use munmap to send the changes to the file movl $91, %eax movl mappedfile, %ebx movl size, %ecx int $0x80 test %eax, %eax jnz badfile # close the open file handle movl $6, %eax movl filehandle, %ebx int $0x80 badfile: movl %eax, %ebx movl $1, %eax int $0x80 |
上面代码中红色标注的部分与英文原著不同,原著使用的是js badfile,但是mmap系统调用的返回值是一个指针值,当指针值为0xb7fff000的地址时,则js badfile就会误认为返回值是负数,也就会误跳转到badfile处,所以需要改为jz badfile,表示当返回值不为0时,就是一个有效的指针,否则就是无效的指针,才需要跳转到badfile处。
上面的代码按照以下6个步骤来完成相关的操作:
- Open the file with read/write access. 使用open系统调用并以读写的方式来打开文件
- Determine the size of the file using the sizefunc function. 通过sizefunc函数来获取文件的尺寸大小
- Map the file to memory using the mmap system call code. 通过mmap系统调用将文件映射到内存
- Convert the memory-mapped file to all uppercase letters. 将内存映射文件里的字符通过convert函数都转为大写字母
- Write the memory-mapped file to the original file using munmap. 使用munmap系统调用将修改后的数据写回原文件
- Close the original file and exit. 通过close系统调用关闭之前open打开的文件描述符
上面几个程式的编译运行结果如下:
$ as -o sizefunc.o sizefunc.s $ as -o convert.o convert.s $ as -o fileconvert.o fileconvert.s $ ld -o fileconvert fileconvert.o sizefunc.o convert.o $ cat cpuid.txt The processor Vendor ID is 'GenuineIntel' The processor Vendor ID is 'GenuineIntel' $ ./fileconvert cpuid.txt $ cat cpuid.txt THE PROCESSOR VENDOR ID IS 'GENUINEINTEL' THE PROCESSOR VENDOR ID IS 'GENUINEINTEL' $ |
可以看到,在运行 ./fileconvert cpuid.txt 后,cpuid.txt里的内容就都变为大写字母了。
我们还可以使用之前"汇编里使用Linux系统调用 (三) 系统调用结束篇"的文章的第2分页里提到的strace工具,来查看fileconvert程式所使用到的相关系统调用:
$ strace ./fileconvert cpuid.txt execve("./fileconvert", ["./fileconvert", "cpuid.txt"], [/* 37 vars */]) = 0 open("cpuid.txt", O_RDWR|O_CREAT, 0644) = 3 _llseek(3, 0, [84], SEEK_END) = 0 old_mmap(NULL, 84, PROT_READ|PROT_WRITE, MAP_SHARED, 3, 0xbfa8b03808088018) = 0xb7720000 munmap(0xb7720000, 84) = 0 close(3) = 0 _exit(0) = ? $ |
需要注意的是,strace工具是以C函数的形式来显示所使用过的系统调用的。
剩下是英文原著第16章的总结部分,限于篇幅,就不多说了。
下一篇开始介绍IA-32平台所提供的一些高级功能。
OK,就到这里,休息,休息一下 o(∩_∩)o~~