什么是汇编语言(二) 高级语言与汇编
zenglong 2013-08-31 14:41:34
前面介绍了和汇编相关的指令字节码部分,这节继续翻译汇编教程英文原著中第一章的后续部分。High-Level Languages(高级编程语言) 如果直接使用纯粹的处理器指令集进行编程确实很困难(尽管看起来好像很cool),即便是最简单的程序都需要程序员写很多的opcode操作码和数据字节...
本文由zengl.com站长对 http://pan.baidu.com/share/link?shareid=3717576860&uk=940392313 汇编教程英文版相应章节进行翻译得来。
另外再附加一个因特尔英文手册的共享链接地址:http://pan.baidu.com/share/link?shareid=2345340326&uk=940392313 (在某些例子中会用到)
前面介绍了和汇编相关的指令字节码部分,这节继续翻译汇编教程英文原著中第一章的后续部分。
High-Level Languages(高级编程语言):
如果直接使用纯粹的处理器指令集进行编程确实很困难(尽管看起来好像很cool),即便是最简单的程序都需要程序员写很多的opcode操作码和数据字节,维护一个大型的全部都由处理器指令代码构成的程序会是一件非常艰巨的任务。为了方便程序员开发和维护程序,高级编程语言就诞生了。
高级编程语言让程序员可以使用简洁的程序术语来写程序,高级语言中提供了很多关键字和方法,可以方便定义变量(变量是存储数据的内存位置的一种引用标识),创建循环结构,以及处理程序的输入输出等。然而处理器并不能直接执行这些高级语言写出来的代码,这些代码必须通过某些方法转化成处理器可以执行的指令格式。下面就根据高级编程语言转为处理器指令格式的方法,进行分类说明。
Types of high-level languages(高级编程语言的类型):
程序员可以选择很多不同的高级编程语言,这些语言可以根据它们在电脑上运行的方式分为两类:
Compiled languages(编译型语言):
很多用于实际应用的应用程序都是采用编译型语言,程序员使用这类语言对应的语法写出程序的逻辑代码,这些文本格式的逻辑代码接着被转化为可以在当前处理器上运行的指令代码,这个转化过程通常被称作编译程序,编译程序实际由两步构成:
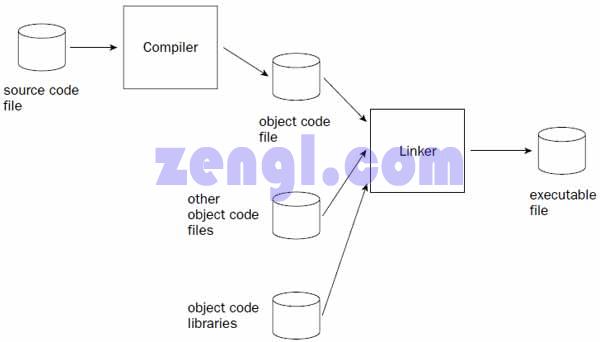
图1-1
编译器将文本格式的高级语言表达式转为能实现程序功能的处理器指令代码。每条语句对应一到多条指令代码,例如下面的高级语言代码:
转成的IA-32指令代码如下:
编译结束后,会生成一个中间文件,即图1-1里的object code file(目标代码文件),该文件里存放的就是上面的IA-32指令(不同的处理器平台生成的指令会有所不同)。这个目标代码文件本身并不能在操作系统中运行。通常,主机操作系统需要一种特殊的可执行文件格式,另外,高级语言创建的程序可能需要利用到多个目标代码文件里的程序功能,所以接下来的步骤就是要将这些组件都组合在一起。
链接器会将编译器生成的目标代码文件或者目标代码库文件(目标代码库里存放的是程序里通用的函数功能)链接在一起,并生成可以在主机操作系统上运行的可执行文件。不过,由于不同的操作系统具有不同的可执行文件格式,所以在微软windows系统下编译链接的程序并不能在Linux环境下运行,反之亦然。
小提示:上面提到的目标代码库文件,里面包含了通用程序功能,库文件分为两种,一种是在编译时直接编译到不同的应用程序里的(称作静态库),另一种是在应用程序运行时动态加载执行的(称作动态库)。
Interpreted languages(解释型语言):
和编译型语言不同,编译型语言生成的可执行程序可以直接在操作系统上运行,但是解释型语言的运行需要一个中间程序,这个程序通常被称作虚拟机,例如译者开发的zengl脚本语言就是通过zengl虚拟机程序解释执行的,zengl虚拟机在加载执行zengl脚本时,会对脚本进行词法扫描,语法分析,最后在虚拟机中生成模拟的指令字节码,虚拟机程序在执行这些模拟的指令字节码时,再跳转到真实的处理器指令代码处执行,每次运行zengl脚本语言时,都会经过这么一个过程,所以脚本的修改马上会生效(当然是针对v1.2.0以后的版本,之前的版本,模拟指令字节码会生成到一个中间文件中,v1.2.0后解释执行合并到了一块,就没有这个中间文件了),BASIC,JAVA(java的中间虚拟机通常被缩写为JVM),PHP等也都有类似的解释型的实现,当然这些语言也都可以转成编译型的语言,只要有相关的编译器即可。
可以看的出来,解释型语言既有它的优势,又有它的劣势,优势在于这种语言编写简单,易学易用,任何修改都可以马上执行来查看效果,而且很多还带有内存垃圾回收机制,不过劣势也显而易见,就是每次执行时都要经过词法扫描,语法分析等,会减慢它的执行速度,即便是生成像JAVA一样的中间字节码文件,在执行这些字节码时,也存在一个解释分析的过程(除非java开发人员再开发一个可以直接执行java中间字节码的真实的硬件处理器),所以解释型语言的速度可能没有编译型语言那么快(之所以用可能是因为程序的执行速度和很多因素有关,即便是编译型语言写出来的程序,如果算法写的不够简洁,或者要加载的其他模块太多,那么速度也快不到哪去)。
High-level language features(高级语言的特点):
如果你是名程序员,那么毫无疑问,高级编程语言的出现让你的工作变得更加容易,高级编程语言最有用的两个特点:可移植性和标准化,这些特点将高级编程语言和汇编语言区分开来。
Portability(可移植性):
前面章节提到过,直接使用处理器指令代码写出来的程序高度依赖电脑上的处理器,每个不同的处理器家族采用不同的指令代码格式,储存数据的方式也不同(有的是little endian小字节序,有的则是big endian大字节序)。为IA-32平台编写的指令代码无法在MIPS处理器平台上运行。
假设你的新程序代码由1万行处理器指令代码来编写(该处理器指令代码假设是SUN SPARC平台的),那么如果要将你的程序移植到英特尔奔腾处理器下的Linux系统中的话,你将要重写所有的源代码,这是件很痛苦的事情。
高级编程语言的编译器可以让你的程序很轻松的移植到其他操作系统和其他处理器平台,只需要在目标平台重新编译一次就可以了。
小提示:如果你的高级语言中使用了某些系统中特定的API接口的话,那么将给移植带来些困难,比如程序中使用了windows系统下特有的API系统接口,那么这个程序在不经修改的情况下,是无法移植到Linux系统下的。zengl语言的虚拟机的C程序源代码之所以可以在几乎不怎么改动的情况下,在windows和linux下都编译成功,是因为zengl源代码使用的都是标准的C接口,而非某个系统所特定的系统接口。
Standardization(标准化):
高级编程语言的另一个有用的特点就是标准化,IEEE(电气电子工程师学会)和ANSI(美国国家标准学会)都为很多不同的高级语言设定了规范。
这意味着你在不同操作系统和平台下使用一个标准编译器编译源代码,得到的可执行程序会产生相同的结果。例如zengl语言的C源代码在windows和linux下分别进行编译,编译后生成的zengl虚拟机程序,在执行脚本时可以产生相同的效果,虽然windows和linux下的编译器并不相同,一个是微软的vs2008使用的c编译器,一种是linux下使用的gcc,但是由于他们都遵从ANSI标准,所以编译后得到的程序可以达到一致的效果。正是这种标准化让前面的可移植性的特点成为可能。
Assembly Language(汇编语言):
在创建大型应用程序时,使用高级语言确实比直接用原始的处理器指令代码写程序要方便的多。但这并不意味着高级语言所生成的最终程序效率一定高,相反,由于高级语言为了增加可移植性和遵从标准化,许多的编译器生成的都是些常规的处理器指令,这意味着,某些高级的处理器芯片中所特有的可以提高效率的指令将不会生成。
例如,在市面上销售的比较新的处理器中都包含一些高级的数学处理指令,这些指令代码使用更大的字节来代表数字(例如64位或128位),从而提高复杂数学表达式的计算速度。不幸的是,很多高级语言的编译器都没有生成这类高级的指令。不过幸运的是,程序员可以使用汇编语言来弥补这个不足,尤其是当你所编写的程序对执行速度要求很高时。当然还需要有精妙的算法,汇编程序加上好的算法就能让你的程序运行效率更高,速度更快。
你无需担心处理器中许多不同的指令集组合,汇编语言使用类似英文单词的助记符来代表单个的处理器指令。这些助记符可以被汇编器很容易的转化为对应的处理器指令代码。
汇编语言由三大部分组成:
Opcode mnemonics (指令操作码助记符):
为了方便编写汇编程序,汇编语言里使用类似英文单词的助记符来代表指令,如下面的处理器指令代码:
可以用如下的汇编语言来编写:
这是一种AT&T的汇编语法格式,具体的语法将在后面的章节中进行说明,这里的汇编语句是和上面的处理器指令代码一一对应的,可以看的出来,push,mov之类的助记符比55 ,89之类的指令要好理解的多。
Defining data (定义程序中要使用的数据):
程序里不光是只有指令,还需要一些数据来参与运算。对于高级语言,会使用变量来定义存放数据的内存区域,例如下面的这几条高级语言的语句:
上面语句中一共定义了三个变量,例如testvalue变量,编译器会将其转为一个内存位置,在该内存位置处存放着默认值150,程序的其他地方就可以使用testvalue变量来读取和修改对应内存里的值。message变量对应内存位置处存放着一段字符串信息,pi变量的内存位置处则存放着一个浮点数。
汇编语言里也可以在内存中定义一些数据项,而且汇编语言能让你对内存中的数据有过多的控制能力,下面就介绍汇编语言里存取数据的方法。
Using memory locations (使用内存位置):
类似于高级语言中定义数据的方法,汇编语言允许你声明一个指向特定内存位置的变量。在汇编语言里定义变量主要由两个部分组成:
将这段汇编语句和前面的高级语言进行比较,你会发现两者很相似,testvalue指向的内存是一个long类型的数据,long类型的数据在内存中占有4个字节的空间,默认值是150,message指向的内存位置就紧挨在testvalue的后面,里面存放的是字符构成的字符串,pi指向的内存为float类型,也是4个字节,默认值是3.14159 。这段代码在内存中的分布情况如下图1-2所示:
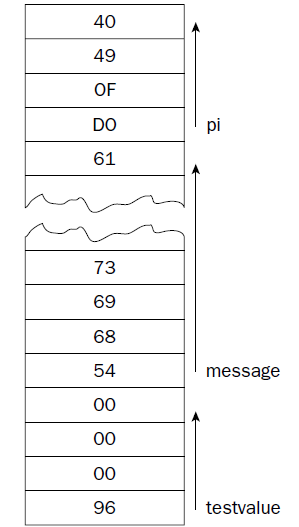
图1-2
上图中96是150的十六进制格式,里面存放的都是十六进制格式的数据。
在汇编程序中就可以使用上面的标签来引用相关的内存起始位置,如下面的汇编语句:
第一条指令是指将testvalue指向的内存位置处的4字节的值加载到EBX寄存器中(在本例中就是将内存里的150传递给EBX),第二条语句对应的指令是将EBX里的值加10,最后一条指令就是将EBX里的值存储到testvalue对应的内存位置中,所以执行完后,testvalue对应的内存里的值应该是160 (上面汇编中涉及到的mov移动数据指令,及add基础数学运算指令,将在以后的章节中进行详细说明)。
Using the stack (使用栈):
汇编语言中,另一种在内存中使用和存取数据的方法叫做stack(栈)。栈是一个特殊的区域,通常用于在程序的功能函数之间传递数据用的,它也可以用于临时的存取数据用。
栈所在的内存区域,保留在电脑分配给应用程序的内存范围的末端,有一个栈指针指向栈中下一次要存取数据的内存位置。栈就好像一叠文件,当往这叠文件上放置新文件时,这个新放置的文件将会被最先取走(假设你只能从这叠文件的顶部取走文件),所以最后存放在栈中的数据会被最先取走。
当在汇编语言里调用某个函数时,你通常会在栈顶为这个函数放置一些数据,这样当函数被调用执行时,它就可以从栈中接收到你传递给它的数据了。
不同的存取数据的方法也将在后面的章节中进行详细说明。
Directives (伪操作符):
汇编语言提供了些特殊的关键字,用以告诉汇编器,当将汇编语句转为指令代码时所需要执行的特殊功能。
在前面的例子中已经接触过的.long ,.ascii ,以及 .float等都是伪操作符,这些伪操作符让汇编器知道标签所指向的内存的数据类型,然后由这些类型来决定给他们分配多少内存空间。
刚刚提到的.long之类的伪操作符是GNU汇编器里提供的,不同的汇编器可以有不同的伪操作符,有的汇编器甚至还提供了类似高级编程语言的loop(循环结构),if-then(条件选择结构)的伪操作符,这些伪操作符让汇编语言变得更容易编写和维护。
在各种伪操作符中最重要的伪操作符之一是.section(段)伪操作符。这个伪操作符定义了汇编程序里不同内存区域的作用,所有的汇编程序都至少要声明三个section(段):
bbs section(未初始化数据段)也是一个静态的内存段,它包含了稍候在程序中将会进行声明的缓冲数据,这个段对应的缓冲数据区域最开始都是被0填充的。
text section(代码段)是内存中存放指令代码的区域,另外,这个区域是固定的,在这个区域里只包含汇编程序所声明的指令代码。
其他的伪操作符会在后面的章节中举例说明。
剩下的就是原著中关于第一章的小结概括,里面的内容在前面都提到过了,就不多说了。
下一章,将讨论IA-32处理器家族的特殊结构,当你了解了硬件的底层原理,你就能写出高效的汇编代码出来。
OK,到这里,休息,休息一下 o(∩_∩)o~~
另外再附加一个因特尔英文手册的共享链接地址:http://pan.baidu.com/share/link?shareid=2345340326&uk=940392313 (在某些例子中会用到)
前面介绍了和汇编相关的指令字节码部分,这节继续翻译汇编教程英文原著中第一章的后续部分。
High-Level Languages(高级编程语言):
如果直接使用纯粹的处理器指令集进行编程确实很困难(尽管看起来好像很cool),即便是最简单的程序都需要程序员写很多的opcode操作码和数据字节,维护一个大型的全部都由处理器指令代码构成的程序会是一件非常艰巨的任务。为了方便程序员开发和维护程序,高级编程语言就诞生了。
高级编程语言让程序员可以使用简洁的程序术语来写程序,高级语言中提供了很多关键字和方法,可以方便定义变量(变量是存储数据的内存位置的一种引用标识),创建循环结构,以及处理程序的输入输出等。然而处理器并不能直接执行这些高级语言写出来的代码,这些代码必须通过某些方法转化成处理器可以执行的指令格式。下面就根据高级编程语言转为处理器指令格式的方法,进行分类说明。
Types of high-level languages(高级编程语言的类型):
程序员可以选择很多不同的高级编程语言,这些语言可以根据它们在电脑上运行的方式分为两类:
- 编译型的语言
- 解释型的语言
Compiled languages(编译型语言):
很多用于实际应用的应用程序都是采用编译型语言,程序员使用这类语言对应的语法写出程序的逻辑代码,这些文本格式的逻辑代码接着被转化为可以在当前处理器上运行的指令代码,这个转化过程通常被称作编译程序,编译程序实际由两步构成:
- 通过编译器将高级语言的程序语句转为原始的指令代码
- 通过链接器再将生成的原始指令代码转成最终可执行的程序
图1-1
编译器将文本格式的高级语言表达式转为能实现程序功能的处理器指令代码。每条语句对应一到多条指令代码,例如下面的高级语言代码:
|
int main() { int i = 1; exit(0); } |
|
55 89 E5 83 EC 08 C7 45 FC 01 00 00 00 83 EC 0C 6A 00 E8 D1 FE FF FF |
编译结束后,会生成一个中间文件,即图1-1里的object code file(目标代码文件),该文件里存放的就是上面的IA-32指令(不同的处理器平台生成的指令会有所不同)。这个目标代码文件本身并不能在操作系统中运行。通常,主机操作系统需要一种特殊的可执行文件格式,另外,高级语言创建的程序可能需要利用到多个目标代码文件里的程序功能,所以接下来的步骤就是要将这些组件都组合在一起。
链接器会将编译器生成的目标代码文件或者目标代码库文件(目标代码库里存放的是程序里通用的函数功能)链接在一起,并生成可以在主机操作系统上运行的可执行文件。不过,由于不同的操作系统具有不同的可执行文件格式,所以在微软windows系统下编译链接的程序并不能在Linux环境下运行,反之亦然。
小提示:上面提到的目标代码库文件,里面包含了通用程序功能,库文件分为两种,一种是在编译时直接编译到不同的应用程序里的(称作静态库),另一种是在应用程序运行时动态加载执行的(称作动态库)。
Interpreted languages(解释型语言):
和编译型语言不同,编译型语言生成的可执行程序可以直接在操作系统上运行,但是解释型语言的运行需要一个中间程序,这个程序通常被称作虚拟机,例如译者开发的zengl脚本语言就是通过zengl虚拟机程序解释执行的,zengl虚拟机在加载执行zengl脚本时,会对脚本进行词法扫描,语法分析,最后在虚拟机中生成模拟的指令字节码,虚拟机程序在执行这些模拟的指令字节码时,再跳转到真实的处理器指令代码处执行,每次运行zengl脚本语言时,都会经过这么一个过程,所以脚本的修改马上会生效(当然是针对v1.2.0以后的版本,之前的版本,模拟指令字节码会生成到一个中间文件中,v1.2.0后解释执行合并到了一块,就没有这个中间文件了),BASIC,JAVA(java的中间虚拟机通常被缩写为JVM),PHP等也都有类似的解释型的实现,当然这些语言也都可以转成编译型的语言,只要有相关的编译器即可。
可以看的出来,解释型语言既有它的优势,又有它的劣势,优势在于这种语言编写简单,易学易用,任何修改都可以马上执行来查看效果,而且很多还带有内存垃圾回收机制,不过劣势也显而易见,就是每次执行时都要经过词法扫描,语法分析等,会减慢它的执行速度,即便是生成像JAVA一样的中间字节码文件,在执行这些字节码时,也存在一个解释分析的过程(除非java开发人员再开发一个可以直接执行java中间字节码的真实的硬件处理器),所以解释型语言的速度可能没有编译型语言那么快(之所以用可能是因为程序的执行速度和很多因素有关,即便是编译型语言写出来的程序,如果算法写的不够简洁,或者要加载的其他模块太多,那么速度也快不到哪去)。
High-level language features(高级语言的特点):
如果你是名程序员,那么毫无疑问,高级编程语言的出现让你的工作变得更加容易,高级编程语言最有用的两个特点:可移植性和标准化,这些特点将高级编程语言和汇编语言区分开来。
Portability(可移植性):
前面章节提到过,直接使用处理器指令代码写出来的程序高度依赖电脑上的处理器,每个不同的处理器家族采用不同的指令代码格式,储存数据的方式也不同(有的是little endian小字节序,有的则是big endian大字节序)。为IA-32平台编写的指令代码无法在MIPS处理器平台上运行。
假设你的新程序代码由1万行处理器指令代码来编写(该处理器指令代码假设是SUN SPARC平台的),那么如果要将你的程序移植到英特尔奔腾处理器下的Linux系统中的话,你将要重写所有的源代码,这是件很痛苦的事情。
高级编程语言的编译器可以让你的程序很轻松的移植到其他操作系统和其他处理器平台,只需要在目标平台重新编译一次就可以了。
小提示:如果你的高级语言中使用了某些系统中特定的API接口的话,那么将给移植带来些困难,比如程序中使用了windows系统下特有的API系统接口,那么这个程序在不经修改的情况下,是无法移植到Linux系统下的。zengl语言的虚拟机的C程序源代码之所以可以在几乎不怎么改动的情况下,在windows和linux下都编译成功,是因为zengl源代码使用的都是标准的C接口,而非某个系统所特定的系统接口。
Standardization(标准化):
高级编程语言的另一个有用的特点就是标准化,IEEE(电气电子工程师学会)和ANSI(美国国家标准学会)都为很多不同的高级语言设定了规范。
这意味着你在不同操作系统和平台下使用一个标准编译器编译源代码,得到的可执行程序会产生相同的结果。例如zengl语言的C源代码在windows和linux下分别进行编译,编译后生成的zengl虚拟机程序,在执行脚本时可以产生相同的效果,虽然windows和linux下的编译器并不相同,一个是微软的vs2008使用的c编译器,一种是linux下使用的gcc,但是由于他们都遵从ANSI标准,所以编译后得到的程序可以达到一致的效果。正是这种标准化让前面的可移植性的特点成为可能。
Assembly Language(汇编语言):
在创建大型应用程序时,使用高级语言确实比直接用原始的处理器指令代码写程序要方便的多。但这并不意味着高级语言所生成的最终程序效率一定高,相反,由于高级语言为了增加可移植性和遵从标准化,许多的编译器生成的都是些常规的处理器指令,这意味着,某些高级的处理器芯片中所特有的可以提高效率的指令将不会生成。
例如,在市面上销售的比较新的处理器中都包含一些高级的数学处理指令,这些指令代码使用更大的字节来代表数字(例如64位或128位),从而提高复杂数学表达式的计算速度。不幸的是,很多高级语言的编译器都没有生成这类高级的指令。不过幸运的是,程序员可以使用汇编语言来弥补这个不足,尤其是当你所编写的程序对执行速度要求很高时。当然还需要有精妙的算法,汇编程序加上好的算法就能让你的程序运行效率更高,速度更快。
你无需担心处理器中许多不同的指令集组合,汇编语言使用类似英文单词的助记符来代表单个的处理器指令。这些助记符可以被汇编器很容易的转化为对应的处理器指令代码。
汇编语言由三大部分组成:
- Opcode mnemonics 指令操作码助记符
- Data sections 数据节
- Directives 汇编伪操作,不会生成指令,只是辅助汇编的一些符号
Opcode mnemonics (指令操作码助记符):
为了方便编写汇编程序,汇编语言里使用类似英文单词的助记符来代表指令,如下面的处理器指令代码:
|
55 89 E5 83 EC 08 C7 45 FC 01 00 00 00 83 EC 0C 6A 00 E8 D1 FE FF FF |
可以用如下的汇编语言来编写:
|
push %ebp mov %esp, %ebp sub $0x8, %esp movl $0x1, -4(%ebp) sub $0xc, %esp push $0x0 call 8048348 |
这是一种AT&T的汇编语法格式,具体的语法将在后面的章节中进行说明,这里的汇编语句是和上面的处理器指令代码一一对应的,可以看的出来,push,mov之类的助记符比55 ,89之类的指令要好理解的多。
Defining data (定义程序中要使用的数据):
程序里不光是只有指令,还需要一些数据来参与运算。对于高级语言,会使用变量来定义存放数据的内存区域,例如下面的这几条高级语言的语句:
|
long testvalue = 150; char message[22] = {“This is a test message”}; float pi = 3.14159; |
上面语句中一共定义了三个变量,例如testvalue变量,编译器会将其转为一个内存位置,在该内存位置处存放着默认值150,程序的其他地方就可以使用testvalue变量来读取和修改对应内存里的值。message变量对应内存位置处存放着一段字符串信息,pi变量的内存位置处则存放着一个浮点数。
汇编语言里也可以在内存中定义一些数据项,而且汇编语言能让你对内存中的数据有过多的控制能力,下面就介绍汇编语言里存取数据的方法。
Using memory locations (使用内存位置):
类似于高级语言中定义数据的方法,汇编语言允许你声明一个指向特定内存位置的变量。在汇编语言里定义变量主要由两个部分组成:
- 一个指向内存位置的标签
- 一个表示内存字节占用数的数据类型和内存中的默认值
|
testvalue: .long 150 message: .ascii “This is a test message” pi: .float 3.14159 |
将这段汇编语句和前面的高级语言进行比较,你会发现两者很相似,testvalue指向的内存是一个long类型的数据,long类型的数据在内存中占有4个字节的空间,默认值是150,message指向的内存位置就紧挨在testvalue的后面,里面存放的是字符构成的字符串,pi指向的内存为float类型,也是4个字节,默认值是3.14159 。这段代码在内存中的分布情况如下图1-2所示:
图1-2
上图中96是150的十六进制格式,里面存放的都是十六进制格式的数据。
在汇编程序中就可以使用上面的标签来引用相关的内存起始位置,如下面的汇编语句:
|
movl testvalue, %ebx addl $10, %ebx movl %ebx, testvalue |
第一条指令是指将testvalue指向的内存位置处的4字节的值加载到EBX寄存器中(在本例中就是将内存里的150传递给EBX),第二条语句对应的指令是将EBX里的值加10,最后一条指令就是将EBX里的值存储到testvalue对应的内存位置中,所以执行完后,testvalue对应的内存里的值应该是160 (上面汇编中涉及到的mov移动数据指令,及add基础数学运算指令,将在以后的章节中进行详细说明)。
Using the stack (使用栈):
汇编语言中,另一种在内存中使用和存取数据的方法叫做stack(栈)。栈是一个特殊的区域,通常用于在程序的功能函数之间传递数据用的,它也可以用于临时的存取数据用。
栈所在的内存区域,保留在电脑分配给应用程序的内存范围的末端,有一个栈指针指向栈中下一次要存取数据的内存位置。栈就好像一叠文件,当往这叠文件上放置新文件时,这个新放置的文件将会被最先取走(假设你只能从这叠文件的顶部取走文件),所以最后存放在栈中的数据会被最先取走。
当在汇编语言里调用某个函数时,你通常会在栈顶为这个函数放置一些数据,这样当函数被调用执行时,它就可以从栈中接收到你传递给它的数据了。
不同的存取数据的方法也将在后面的章节中进行详细说明。
Directives (伪操作符):
汇编语言提供了些特殊的关键字,用以告诉汇编器,当将汇编语句转为指令代码时所需要执行的特殊功能。
在前面的例子中已经接触过的.long ,.ascii ,以及 .float等都是伪操作符,这些伪操作符让汇编器知道标签所指向的内存的数据类型,然后由这些类型来决定给他们分配多少内存空间。
刚刚提到的.long之类的伪操作符是GNU汇编器里提供的,不同的汇编器可以有不同的伪操作符,有的汇编器甚至还提供了类似高级编程语言的loop(循环结构),if-then(条件选择结构)的伪操作符,这些伪操作符让汇编语言变得更容易编写和维护。
在各种伪操作符中最重要的伪操作符之一是.section(段)伪操作符。这个伪操作符定义了汇编程序里不同内存区域的作用,所有的汇编程序都至少要声明三个section(段):
- A data section 一个数据段
- A bss section 一个未初始化数据段
- A text section 包含了可执行指令代码的段
bbs section(未初始化数据段)也是一个静态的内存段,它包含了稍候在程序中将会进行声明的缓冲数据,这个段对应的缓冲数据区域最开始都是被0填充的。
text section(代码段)是内存中存放指令代码的区域,另外,这个区域是固定的,在这个区域里只包含汇编程序所声明的指令代码。
其他的伪操作符会在后面的章节中举例说明。
剩下的就是原著中关于第一章的小结概括,里面的内容在前面都提到过了,就不多说了。
下一章,将讨论IA-32处理器家族的特殊结构,当你了解了硬件的底层原理,你就能写出高效的汇编代码出来。
OK,到这里,休息,休息一下 o(∩_∩)o~~