Python的基本语法
zenglong 2014-11-28 15:36:17
如果已经在前一章的基础上,安装好了python的话,这里以linux系统为例来进行说明,就可以打开终端,输入python,接着会出现python的交互式输入界面,我们可以在该界面里测试一些简单的代码...
页面导航:
英文教程的下载地址:
本篇文章是根据英文教程《Python Tutorial》来写的学习笔记。该英文教程的下载地址如下:
百度盘地址:http://pan.baidu.com/s/1c0eXSQG
DropBox地址:点此进入DropBox链接
Google Drive:点此进入Google Drive链接
这是学习笔记,不是翻译,因此,有些内容,作者会略过。以下记录主要是根据英文教程的第三章来写的。(文章中的部分链接,可能需要通过代理访问!)
简单的python程式:
如果已经在前一章的基础上,安装好了python的话,这里以linux系统为例来进行说明,就可以打开终端,输入python,接着会出现python的交互式输入界面,我们可以在该界面里测试一些简单的代码:
上面使用print函数来打印出一条"hello"的字符串信息,接着通过quit函数来退出交互式输入界面,有关函数的概念在以后的章节里会进行介绍,这里只需要先了解即可。
当然我们也可以将Python代码写入到某个文件里,然后让python去执行该文件里的代码,假设我们在test.py文件中输入如下代码:
然后,就可以在命令行下执行该文件里的代码了:
上面只需在python后面,添加一个文件名作为参数即可。
此外,如果想直接运行test.py文件的话,可以在文件的开头添加一个python的路径信息:
这里在文件的开头,通过#!来指明python解释器的路径(有关#!的详细说明,请参考 http://zh.wikipedia.org/wiki/Shebang 该链接对应的文章),你需要根据自己系统里的python位置来调整这个路径信息,接着,就可以输入如下命令来直接运行该文件里的代码了:
上面先通过chmod命令为test.py添加可执行权限(通过+x参数来指定),然后就可以输入./test.py直接运行文件里的代码了(./表示当前目录的意思,不可以少),在执行时,会先根据#!指明的路径信息去加载python,再由python去解释执行文件里的代码,#开头的内容,在python中,会被当作注释,因此,#!/usr/local/bin/python语句不会对执行产生影响。
Python标识符:
Python标识符用于表示python中变量,函数,类,模块或对象的名称(变量、函数等概念在以后的章节中会进行介绍)。
标识符由字母(大写或小写)、下划线("_")或数字(0-9)组成。
不过,这里需要注意的是:标识符的第一个字符必须是字母或下划线,不可以是数字。
你可以在python的交互式界面中,测试标识符:
上面测试了几个标识符(在这里其实就是变量的名称):abc、_bbc、_123abc_这三个都是有效的标识符,而123abc与234@abc则不是有效的标识符(因此就显示出了SyntaxError的语法错误)。
Python的标识符是区分大小写的,abc与ABC是两个不同的标识符:
从上面的输出可以看到,abc与ABC是两个不同的标识符,它们分别可以接收不同的值,代表两个完全不同的变量。
以下划线开头的标识符是有特殊意义的。
1):以单下划线开头的标识符(主要是出现于类属性里),表示该标识符是私有的,当然只是结构上约定的,要访问的话,还是可以直接访问的。
2):以双下划线开头的标识符(主要是出现于类属性里),表示该标识符是强制私有的,直接访问的话,是访问不了的。
3):以双下划线开头和结尾的标识符(主要是出现于类方法中),是python里的特殊标识符。
可以通过下面的例子来加深理解(暂时只需了解即可,这里的类,属性,方法的概念会在以后的章节中进行介绍):
从上面的例子中,可以看到,双下划线开头和结尾的__init__是一个Python里的特殊标识符(用于类的初始化),单下划线开头的_a则是一个私有标识符,表示作者不希望该标识符被外界访问,但是如果你要通过ap._a的方式直接访问的话,还是可以访问到的,所以只是一种约定。而__a则是更为强制性的私有标识符,对它进行直接访问,则会出现no attribute '__a'的错误。有关单下划线与双下划线的更多内容,可以参考 http://bbs.zengl.com/thread-46-1-1.html 对应的帖子。
Python关键字:
Python关键字指的是Python中有特殊含义的标识符,用户不可以在自己的程式中定义这些标识符,Python里的关键字如下表所示:
所有的关键字都是由小写字母组成。
Python以缩进形式组织代码:
在C语言里,是以大括号的形式来组织代码块的,如下面的代码:
在python里,就需要用到缩进的方式来组织代码:
缩进不一定要使用tab符,只要某行的列数,比上一行大,那么该行就在上一行的基础上发生了缩进。例如下面的代码:
第二行print语句的开头,只有一个空格符,因此,print的第一个'p'字符的col列数为1(python内部的col是从0开始计数的),而第一行if语句的首字符'i'的col为0,第二行的col比第一行的大,因此,第二行就在第一行的基础上,发生了缩进。
上面是单个语句构成代码块的情况,如果是多条语句要构成代码块的话,在C语言里,只需将这些语句都包含在大括号里即可:
在python里,则需要保证代码块里的多条语句,具有相同的缩进,如下所示:
也就是,要确保上面三条print语句的首字符'p'的col(列数)是相同的。这里就有一个col的计算问题,即:当某行的开头既有空格符,又有tab制表符时,col是如何计算的。
在python内部,有一个tabsize成员,默认情况下是8,也就是tab边界是8的倍数,tab边界指的是,当python处理一个tab字符时,始终会将tab后面的字符定位到最接近的tab边界上,例如,下面的代码:
这里用\s来表示一个空格符,用\t来表示一个tab符,那么即便\t前面有三个\s空格符,该tab符后面的p字符也只会被定位到tab边界上,在这里也就是col等于8的位置,不管\t前面是4个,5个,还是6个空格符,后面的p都只会被定位在col为8的边界位置,除非,空格数大于或等于8,当空格数等于8时,tab符就会将首字符'p'定位到下一个col等于16的边界位置。(其实就是跟编辑器的算法是一致的,你可以试着在编辑器里输入4个空格符,再输入一个tab符,当编辑器的tabsize的值为8时,tab后面的字符就会被定位到第一个tab边界上)
python就是根据col值来判断缩进的,由于python的tabsize(制表符宽度)为8,因此,在编辑python的源代码时,需要将编辑器的tabsize也设置为8,下面是Gedit编辑器的设置界面:
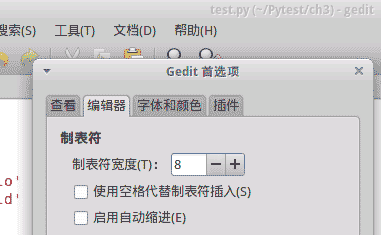
图1
这样就可以防止在编辑器中,因为tab缩进而出现语法错误。
此外,必须在有效的关键字后,才能进行缩进。有效的关键字如下:
上面的suite表示代码块,因此,只能在if、for之类的语句后面进行缩进。所以下面的代码就是有语法错误的:
第二条print语句在第一条print语句的基础上发生了缩进,但是,print并非有效的可以进行缩进的关键字,因此就会报语法错误。
上面介绍的都是indent(向右缩进),其实,在python里还有一个dedent向左缩进,例如下面的代码:
代码中,最后一条print 'end'语句的第一个字符'p'的col值(即列数)为0,比上一行print语句的首字符的col值要小,因此,print 'end'语句就是在上一行的基础上发生了向左缩进,由于第一行if a==2:语句的首字符的col值也为0,所以,print 'end'语句就与if a==2:语句具有相同的缩进,这两条代码就属于同一个代码块。if a==2:语句及其包含的代码块执行完后,接着始终会去执行print 'end'指令。
向左缩进的语句,必须与之前某一行的代码具有相同的缩进,否则就会因为不属于任何一个代码块而发生语法错误,例如下面的代码:
我们将上面的代码保存到test.py文件里,再运行一下,就会得到如下结果:
可以看到,运行时,会出现IndentationError的缩进错误,具体错误原因为:unindent does not match any outer indentation level,即:最后一行print 'end'语句向左缩进后,得到的col值与之前任何一行的代码的col值都不相同,因此,该语句不属于任何一个代码块,当然就会报错了。
以上就是和缩进相关的内容,如果想更详细的了解缩进的原理的话,可以参考 http://bbs.zengl.com/thread-47-1-1.html 该链接对应的文章。
多行语句:
如果要将单条语句分多行来写的话,可以使用连接符即(\),例如下面的例子:
上面a与b得到的结果是一样的,只不过,b所在的语句,在行尾处,使用(\)来分成了几行。
如果语句在中括号,大括号,或小括号里的话,则不需要使用连接符,例如:
Python中的引号:
python中有三种引号:单引号('),双引号("),以及三重引号('''或""")。它们都可以用来引用字符串。
单引号与双引号在引用字符串时是等价的,例如下面两条代码得到的字符串都是一样的:
只不过,在单引号引用的字符串里面如果还要使用单引号的话,字符串内部的单引号需要用(\')来转义:
而双引号里面引用单引号时,则不需要转义:
同理,双引号引用的字符串里面要包含双引号的话,内部的双引号需要(\")来进行转义:
而单引号里面引用双引号时,则不需要转义:
当然,你非要对里面的双引号进行转义也是可以的:
此外,单引号与双引号所引用的字符串只能写在一行,如果要分几行来写的话,就需要用到前面介绍过的连接符(\):
三重引号可以使用三个单引号(''')的形式,也可以使用三个双引号(""")的形式,三重引号所包含的字符串可以跨越多行,它会将字符串里的信息,包括其中的隐式换行符都原样保存下来:
我们可以将上面的代码保存到test.py文件中,然后在命令行下进行测试,得到的结果如下:
可以看到,字符串信息被原样保存了下来。三重引号里还可以包含\n之类的转义字符,它也会像单引号与双引号那样,对这些转义字符进行处理:
将上面代码保存到test.py后,测试结果如下:
可以看到,\n即换行符对应的转义字符,得到了正确的处理。
最后,三重引号所引用的字符串中,如果要包含单引号或双引号的话,单引号与双引号都可以不使用转义字符:
Python中的注释:
Python中使用#来表示注释,例如下面的代码:
上面#开头的字符串都会被当作注释,这些注释信息,都会被python解释器给忽略掉,除非#位于字符串里面:
字符串里面的#,就会被解析为字符串中的一个字符,可以被print语句输出显示出来。
在网上,有的文章里面,提到三重引号可以引用多行注释,其实,python中的注释只有一个,就是#,三重引号只不过在某些场合可以被用作doc string即可以显示在帮助信息里面的字符串,但三重引号引用的始终是一个字符串,该字符串会被python正常解析和处理,而不会像注释那样被忽略掉。
例如,可以进行下面的测试:
上面在定义bla方法时,在方法的开头用三重引号定义了一条Print the answer的字符串信息, 该字符串会被当作该方法的帮助信息,被保存在bla方法的__doc__属性里,可以使用bla.__doc__来查看到这条信息,也可以通过help(bla)方法来查看到这条信息。
而使用注释的话,得到的结果就会是:
使用#开头的注释的话,这条信息就会被忽略掉。
因此,三重引号虽然在上面那种场合下,看起来像注释,但是和注释还是有区别的。
python里,真正的多行注释,也都是由#开头的单行注释拼凑起来的:
交互式输入中使用空白行:
在python交互式界面下,当使用if之类的语句时,python会进入代码块的输入状态:
在代码块输入状态下,左侧的>>>就会变为... ,要结束代码块输入状态的话,可以在最后一条代码块语句后面,直接输入一个回车符即产生一个空白行,这样它就会返回到原始的>>>的提示符下:
上面在输入print 'world'并按回车后,在进入到下一个...的提示符时,再按一次回车,这样就产生了一个空白行,就可以退出代码块的输入状态了。
空白行仅在交互式输入中起到作用,在脚本文件里是没有这个作用的。
将多行语句写到同一行:
如果要将多行语句写到同一行的话,可以用分号将这些语句分隔开来,例如,下面这段代码是原始的多行语句:
我们可以用分号将它们置于同一行中:
得到的结果是一样的。
限于篇幅,本章就先到这里。
OK,休息,休息一下 o(∩_∩)o~~
- 英文教程的下载地址
- 简单的python程式
- Python标识符
- Python保留字
- Python以缩进形式组织代码
- 多行语句
- Python中的引号
- Python中的注释
- 交互式输入中使用空白行
- 将多行语句写到同一行
英文教程的下载地址:
本篇文章是根据英文教程《Python Tutorial》来写的学习笔记。该英文教程的下载地址如下:
百度盘地址:http://pan.baidu.com/s/1c0eXSQG
DropBox地址:点此进入DropBox链接
Google Drive:点此进入Google Drive链接
这是学习笔记,不是翻译,因此,有些内容,作者会略过。以下记录主要是根据英文教程的第三章来写的。(文章中的部分链接,可能需要通过代理访问!)
简单的python程式:
如果已经在前一章的基础上,安装好了python的话,这里以linux系统为例来进行说明,就可以打开终端,输入python,接着会出现python的交互式输入界面,我们可以在该界面里测试一些简单的代码:
[email protected]:~$ python Python 2.7.8 (default, Nov 26 2014, 11:28:30) [GCC 4.5.3] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> print("hello"); hello >>> quit() [email protected]:~$ |
上面使用print函数来打印出一条"hello"的字符串信息,接着通过quit函数来退出交互式输入界面,有关函数的概念在以后的章节里会进行介绍,这里只需要先了解即可。
当然我们也可以将Python代码写入到某个文件里,然后让python去执行该文件里的代码,假设我们在test.py文件中输入如下代码:
print("hello world!"); print("welcome to python!"); |
然后,就可以在命令行下执行该文件里的代码了:
[email protected]:~/Pytest/ch3$ python test.py hello world! welcome to python! [email protected]:~/Pytest/ch3$ |
上面只需在python后面,添加一个文件名作为参数即可。
此外,如果想直接运行test.py文件的话,可以在文件的开头添加一个python的路径信息:
#!/usr/local/bin/python
print("hello world!");
print("welcome to python!");
|
这里在文件的开头,通过#!来指明python解释器的路径(有关#!的详细说明,请参考 http://zh.wikipedia.org/wiki/Shebang 该链接对应的文章),你需要根据自己系统里的python位置来调整这个路径信息,接着,就可以输入如下命令来直接运行该文件里的代码了:
[email protected]:~/Pytest/ch3$ chmod +x test.py [email protected]:~/Pytest/ch3$ ./test.py hello world! welcome to python! [email protected]:~/Pytest/ch3$ |
上面先通过chmod命令为test.py添加可执行权限(通过+x参数来指定),然后就可以输入./test.py直接运行文件里的代码了(./表示当前目录的意思,不可以少),在执行时,会先根据#!指明的路径信息去加载python,再由python去解释执行文件里的代码,#开头的内容,在python中,会被当作注释,因此,#!/usr/local/bin/python语句不会对执行产生影响。
Python标识符:
Python标识符用于表示python中变量,函数,类,模块或对象的名称(变量、函数等概念在以后的章节中会进行介绍)。
标识符由字母(大写或小写)、下划线("_")或数字(0-9)组成。
不过,这里需要注意的是:标识符的第一个字符必须是字母或下划线,不可以是数字。
你可以在python的交互式界面中,测试标识符:
[email protected]:~/Pytest/ch3$ python Python 2.7.8 (default, Nov 26 2014, 11:28:30) [GCC 4.5.3] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> abc = 3 >>> print abc 3 >>> _bbc = 15 >>> print _bbc 15 >>> _123abc_ = 3345 >>> print _123abc_ 3345 >>> 123abc = 33 File " |
上面测试了几个标识符(在这里其实就是变量的名称):abc、_bbc、_123abc_这三个都是有效的标识符,而123abc与234@abc则不是有效的标识符(因此就显示出了SyntaxError的语法错误)。
Python的标识符是区分大小写的,abc与ABC是两个不同的标识符:
[email protected]:~/Pytest/ch3$ python Python 2.7.8 (default, Nov 26 2014, 11:28:30) [GCC 4.5.3] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> abc = 123 >>> ABC = 456 >>> print abc 123 >>> print ABC 456 >>> quit() [email protected]:~/Pytest/ch3$ |
从上面的输出可以看到,abc与ABC是两个不同的标识符,它们分别可以接收不同的值,代表两个完全不同的变量。
以下划线开头的标识符是有特殊意义的。
1):以单下划线开头的标识符(主要是出现于类属性里),表示该标识符是私有的,当然只是结构上约定的,要访问的话,还是可以直接访问的。
2):以双下划线开头的标识符(主要是出现于类属性里),表示该标识符是强制私有的,直接访问的话,是访问不了的。
3):以双下划线开头和结尾的标识符(主要是出现于类方法中),是python里的特殊标识符。
可以通过下面的例子来加深理解(暂时只需了解即可,这里的类,属性,方法的概念会在以后的章节中进行介绍):
[email protected]:~/Pytest/ch3$ python Python 2.7.8 (default, Nov 26 2014, 11:28:30) [GCC 4.5.3] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> class A: ... def __init__(self): ... self.a = 'a'; ... self._a = '_a'; ... self.__a = '__a'; ... >>> ap = A() >>> ap.a 'a' >>> ap._a '_a' >>> ap.__a Traceback (most recent call last): File " |
从上面的例子中,可以看到,双下划线开头和结尾的__init__是一个Python里的特殊标识符(用于类的初始化),单下划线开头的_a则是一个私有标识符,表示作者不希望该标识符被外界访问,但是如果你要通过ap._a的方式直接访问的话,还是可以访问到的,所以只是一种约定。而__a则是更为强制性的私有标识符,对它进行直接访问,则会出现no attribute '__a'的错误。有关单下划线与双下划线的更多内容,可以参考 http://bbs.zengl.com/thread-46-1-1.html 对应的帖子。
Python关键字:
Python关键字指的是Python中有特殊含义的标识符,用户不可以在自己的程式中定义这些标识符,Python里的关键字如下表所示:
| and | exec | not |
| assert | finally | or |
| break | for | pass |
| class | from | |
| continue | global | raise |
| def | if | return |
| del | import | try |
| elif | in | while |
| else | is | with |
| except | lambda | yield |
所有的关键字都是由小写字母组成。
Python以缩进形式组织代码:
在C语言里,是以大括号的形式来组织代码块的,如下面的代码:
if(a==b) { printf("a==b"); } |
在python里,就需要用到缩进的方式来组织代码:
if a==b: print 'a=b' |
缩进不一定要使用tab符,只要某行的列数,比上一行大,那么该行就在上一行的基础上发生了缩进。例如下面的代码:
if a==b: print 'a==b' |
第二行print语句的开头,只有一个空格符,因此,print的第一个'p'字符的col列数为1(python内部的col是从0开始计数的),而第一行if语句的首字符'i'的col为0,第二行的col比第一行的大,因此,第二行就在第一行的基础上,发生了缩进。
上面是单个语句构成代码块的情况,如果是多条语句要构成代码块的话,在C语言里,只需将这些语句都包含在大括号里即可:
if(a==b) { printf("a==b"); printf("hello"); printf("world"); } |
在python里,则需要保证代码块里的多条语句,具有相同的缩进,如下所示:
if a==b: print 'a=b' print 'hello' print 'world' |
也就是,要确保上面三条print语句的首字符'p'的col(列数)是相同的。这里就有一个col的计算问题,即:当某行的开头既有空格符,又有tab制表符时,col是如何计算的。
在python内部,有一个tabsize成员,默认情况下是8,也就是tab边界是8的倍数,tab边界指的是,当python处理一个tab字符时,始终会将tab后面的字符定位到最接近的tab边界上,例如,下面的代码:
| \s\s\s\tprint 'a=b' |
这里用\s来表示一个空格符,用\t来表示一个tab符,那么即便\t前面有三个\s空格符,该tab符后面的p字符也只会被定位到tab边界上,在这里也就是col等于8的位置,不管\t前面是4个,5个,还是6个空格符,后面的p都只会被定位在col为8的边界位置,除非,空格数大于或等于8,当空格数等于8时,tab符就会将首字符'p'定位到下一个col等于16的边界位置。(其实就是跟编辑器的算法是一致的,你可以试着在编辑器里输入4个空格符,再输入一个tab符,当编辑器的tabsize的值为8时,tab后面的字符就会被定位到第一个tab边界上)
python就是根据col值来判断缩进的,由于python的tabsize(制表符宽度)为8,因此,在编辑python的源代码时,需要将编辑器的tabsize也设置为8,下面是Gedit编辑器的设置界面:
图1
这样就可以防止在编辑器中,因为tab缩进而出现语法错误。
此外,必须在有效的关键字后,才能进行缩进。有效的关键字如下:
if test : suite for exprlist in testlist : suite while test : suite def Name() : suite class Name : suite try : suite except : suite finally : suite |
上面的suite表示代码块,因此,只能在if、for之类的语句后面进行缩进。所以下面的代码就是有语法错误的:
if a==b: print 'a=b' print 'hello' |
第二条print语句在第一条print语句的基础上发生了缩进,但是,print并非有效的可以进行缩进的关键字,因此就会报语法错误。
上面介绍的都是indent(向右缩进),其实,在python里还有一个dedent向左缩进,例如下面的代码:
if a==2: if a==b: print 'a=b' print 'hello' print 'end' |
代码中,最后一条print 'end'语句的第一个字符'p'的col值(即列数)为0,比上一行print语句的首字符的col值要小,因此,print 'end'语句就是在上一行的基础上发生了向左缩进,由于第一行if a==2:语句的首字符的col值也为0,所以,print 'end'语句就与if a==2:语句具有相同的缩进,这两条代码就属于同一个代码块。if a==2:语句及其包含的代码块执行完后,接着始终会去执行print 'end'指令。
向左缩进的语句,必须与之前某一行的代码具有相同的缩进,否则就会因为不属于任何一个代码块而发生语法错误,例如下面的代码:
a=2; b=2; if a==2: if a==b: print 'a=b' print 'hello' print 'end' |
我们将上面的代码保存到test.py文件里,再运行一下,就会得到如下结果:
[email protected]:~/Pytest/ch3$ python test.py File "test.py", line 7 print 'end' ^ IndentationError: unindent does not match any outer indentation level [email protected]:~/Pytest/ch3$ |
可以看到,运行时,会出现IndentationError的缩进错误,具体错误原因为:unindent does not match any outer indentation level,即:最后一行print 'end'语句向左缩进后,得到的col值与之前任何一行的代码的col值都不相同,因此,该语句不属于任何一个代码块,当然就会报错了。
以上就是和缩进相关的内容,如果想更详细的了解缩进的原理的话,可以参考 http://bbs.zengl.com/thread-47-1-1.html 该链接对应的文章。
多行语句:
如果要将单条语句分多行来写的话,可以使用连接符即(\),例如下面的例子:
a = 2 + 3 + 4 print a b=2 + \ 3 + \ 4 print b |
上面a与b得到的结果是一样的,只不过,b所在的语句,在行尾处,使用(\)来分成了几行。
如果语句在中括号,大括号,或小括号里的话,则不需要使用连接符,例如:
days = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'] |
Python中的引号:
python中有三种引号:单引号('),双引号("),以及三重引号('''或""")。它们都可以用来引用字符串。
单引号与双引号在引用字符串时是等价的,例如下面两条代码得到的字符串都是一样的:
a = 'hello world' b = "hello world" |
只不过,在单引号引用的字符串里面如果还要使用单引号的话,字符串内部的单引号需要用(\')来转义:
| a = '\'hello world\'' |
而双引号里面引用单引号时,则不需要转义:
| a = "'hello world'" |
同理,双引号引用的字符串里面要包含双引号的话,内部的双引号需要(\")来进行转义:
| a = "\"hello world\"" |
而单引号里面引用双引号时,则不需要转义:
| a = '"hello world"' |
当然,你非要对里面的双引号进行转义也是可以的:
| a = '\"hello world\"' |
此外,单引号与双引号所引用的字符串只能写在一行,如果要分几行来写的话,就需要用到前面介绍过的连接符(\):
|
a = 'hello \ world' |
三重引号可以使用三个单引号(''')的形式,也可以使用三个双引号(""")的形式,三重引号所包含的字符串可以跨越多行,它会将字符串里的信息,包括其中的隐式换行符都原样保存下来:
a = """hello world welcome to china""" print a |
我们可以将上面的代码保存到test.py文件中,然后在命令行下进行测试,得到的结果如下:
[email protected]:~/Pytest/ch3$ python test.py hello world welcome to china [email protected]:~/Pytest/ch3$ |
可以看到,字符串信息被原样保存了下来。三重引号里还可以包含\n之类的转义字符,它也会像单引号与双引号那样,对这些转义字符进行处理:
a = """hello world \n welcome to china""" print a |
将上面代码保存到test.py后,测试结果如下:
[email protected]:~/Pytest/ch3$ python test.py hello world welcome to china [email protected]:~/Pytest/ch3$ |
可以看到,\n即换行符对应的转义字符,得到了正确的处理。
最后,三重引号所引用的字符串中,如果要包含单引号或双引号的话,单引号与双引号都可以不使用转义字符:
a = """hello "world" 'welcome' to china""" print a |
Python中的注释:
Python中使用#来表示注释,例如下面的代码:
#!/usr/bin/python # First comment print "Hello, Python!"; # second comment |
上面#开头的字符串都会被当作注释,这些注释信息,都会被python解释器给忽略掉,除非#位于字符串里面:
#!/usr/bin/python # First comment print "Hello,# Python!"; # second comment |
字符串里面的#,就会被解析为字符串中的一个字符,可以被print语句输出显示出来。
在网上,有的文章里面,提到三重引号可以引用多行注释,其实,python中的注释只有一个,就是#,三重引号只不过在某些场合可以被用作doc string即可以显示在帮助信息里面的字符串,但三重引号引用的始终是一个字符串,该字符串会被python正常解析和处理,而不会像注释那样被忽略掉。
例如,可以进行下面的测试:
[email protected]:~/Pytest/ch3$ python Python 2.7.8 (default, Nov 26 2014, 11:28:30) [GCC 4.5.3] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> def bla(): ... """Print the answer""" ... print 42 ... >>> bla.__doc__ 'Print the answer' >>> help(bla) Help on function bla in module __main__: bla() Print the answer >>> quit() [email protected]:~/Pytest/ch3$ |
上面在定义bla方法时,在方法的开头用三重引号定义了一条Print the answer的字符串信息, 该字符串会被当作该方法的帮助信息,被保存在bla方法的__doc__属性里,可以使用bla.__doc__来查看到这条信息,也可以通过help(bla)方法来查看到这条信息。
而使用注释的话,得到的结果就会是:
[email protected]:~/Pytest/ch3$ python Python 2.7.8 (default, Nov 26 2014, 11:28:30) [GCC 4.5.3] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> def bla(): ... # print the answer ... print 42 ... >>> bla.__doc__ >>> help(bla) Help on function bla in module __main__: bla() >>> quit() [email protected]:~/Pytest/ch3$ |
使用#开头的注释的话,这条信息就会被忽略掉。
因此,三重引号虽然在上面那种场合下,看起来像注释,但是和注释还是有区别的。
python里,真正的多行注释,也都是由#开头的单行注释拼凑起来的:
|
# This is a comment. # This is a comment, too. # This is a comment, too. # I said that already. print 'hello world' |
交互式输入中使用空白行:
在python交互式界面下,当使用if之类的语句时,python会进入代码块的输入状态:
[email protected]:~/Pytest/ch3$ python Python 2.7.8 (default, Nov 26 2014, 11:28:30) [GCC 4.5.3] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> a = 2 >>> if a==2: ... print 'a=2' ... print 'hello' ... print 'world' |
在代码块输入状态下,左侧的>>>就会变为... ,要结束代码块输入状态的话,可以在最后一条代码块语句后面,直接输入一个回车符即产生一个空白行,这样它就会返回到原始的>>>的提示符下:
[email protected]:~/Pytest/ch3$ python Python 2.7.8 (default, Nov 26 2014, 11:28:30) [GCC 4.5.3] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> a = 2 >>> if a==2: ... print 'a=2' ... print 'hello' ... print 'world' ... a=2 hello world >>> quit() [email protected]:~/Pytest/ch3$ |
上面在输入print 'world'并按回车后,在进入到下一个...的提示符时,再按一次回车,这样就产生了一个空白行,就可以退出代码块的输入状态了。
空白行仅在交互式输入中起到作用,在脚本文件里是没有这个作用的。
将多行语句写到同一行:
如果要将多行语句写到同一行的话,可以用分号将这些语句分隔开来,例如,下面这段代码是原始的多行语句:
|
a=2 b=3 c=4 print a print b print c |
我们可以用分号将它们置于同一行中:
| a=2; b=3; c=4; print a; print b; print c |
得到的结果是一样的。
限于篇幅,本章就先到这里。
OK,休息,休息一下 o(∩_∩)o~~